Flutter で画像を一覧表示するときに注意すること
画像を多く表示する画面が複数あるアプリの開発に今携わっていて、注意点をチーム内でどう共有しようかと考えている間に一つの記事になりそうだと思ったので書くことにしました。
大量読み込みが起こりやすい
Flutter で画像を含む一覧を作るのは簡単ですが、あまり気にせずに作ると大量の画像が一気に読み込まれたりメモリを使いすぎたりすることがあり、大きな一覧では特に注意が必要です。
ネットワークからの読み込み数、転送量/通信量、メモリ使用量などを減らす方法はパジネーションや小さなサムネイル画像など様々ですが、この記事では一般的な方法は省略して Flutter での方法に絞ります。
Column や Row に注意

Column に 20 個の要素があって画像を含んでいる例です。1
SingleChildScrollView( child: Column( children: [ for (var i = 0; i < 20; i++) ...[ SizedBox( height: 100.0, child: Image.network('https://xxxxx.xxx/$i.jpg'), ), const Divider(), ], ], ), )
画面内に見えている要素は三つだけですが、画像はすぐに 20 枚すべてが読み込まれます。
Column や Row ではすぐにマウントされてビルドまで(おそらく描画も)が一気に行われるからです。
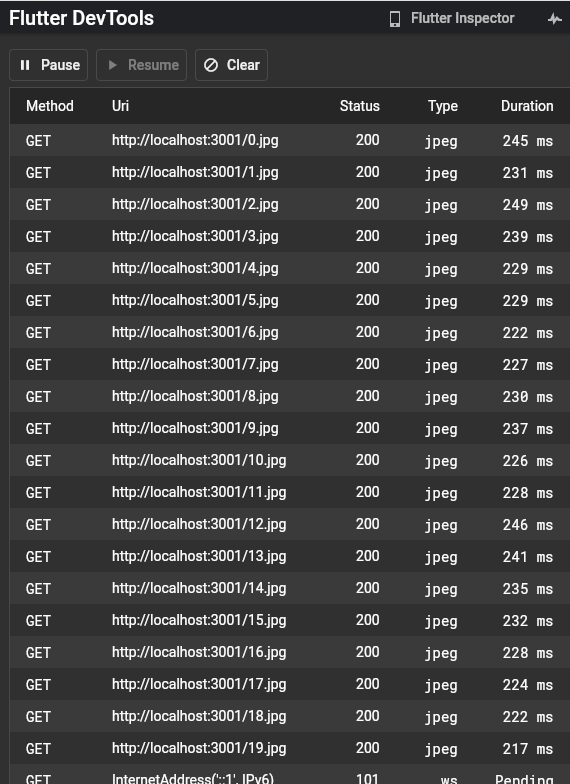
全部読み込んでしまう様子を DevTools の Network view で見ることができます。
ウェブならブラウザの開発ツールでも確認できます。
メモリ使用量にも影響
画像がすぐに全部用意されるのはメモリが不足する原因にもなります。
そのことは DevTools の Memory view で確認できます。

これは 20 個の要素一つずつに 0.5 ~ 1.5 MB 程の画像がある Column で試した様子です。
最初に使用量が増えた後、スクロールしても変化がなくて平らになっています。
この程度のサイズと数なら大丈夫ですが、酷いとアプリが落ちるくらいになります。
小さなサムネイル画像を使って抑えても大量になれば使用量が大きくなるので、この先の対策も併せて必要です。
補足
Flutter の画像のキャッシュは ImageCache で設定されています。
初期値は数(maximumSize)が 1,000、大きさ(maximumSizeBytes)が 100 MiB です。
それを超えると、最後に使ってから時間が経過している画像から自動的に消去されていきます。
メモリを使いすぎないようにその値を変えれば、メモリが少ない端末で OOM が起こるのを防げそうです。2
// 上限を30MiBに抑える例 PaintingBinding.instance.imageCache.maximumSizeBytes = 30 << 20;
ただし、サーバから一気に読み込んでしまう問題は解決しませんし、キャッシュが消えた画像が再び必要になったときに取得しなおさないといけません。
この後で説明する他の方法を使うほうがいいと思います。
対策 - ListView や GridView を使う
Column / Row は要素が少ない一覧に限って使い、多ければ ListView や GridView を使いましょう。
ListView を使うと、表示部分とその前後(cacheExtent で指定したサイズ)から外れた範囲の画像が読み込まれるのを防ぐことができます。3
失敗例
しかし ListView にするだけでは不十分です。
ListView( // 検証しやすくするために見える範囲のみ描画されるよう設定 cacheExtent: 0.0, children: [ for (var i = 0; i < 20; i++) ...[ child: Image.network('https://xxxxx.xxx/$i.jpg'), const Divider(), ], ], )
下のスクリーンショットは、一覧を表示した瞬間のものです。
たくさんの Divider が見えていますね。
読み込まれる前は画像の高さがゼロのまま各要素が表示され、多くの要素が表示範囲内にある状態になります。

この例では Divider の padding の分の高さがありますが、それでも 20 個の要素が見えてしまっています。
もし画像のみの要素なら未表示時には高さがゼロなので、要素数が大量であっても全部が表示範囲に入ります。
表示範囲に入ると画像は読み込みが開始されて先ほど DevTools で見たのと同じことが起こりますので、ListView を使うだけでは確実な対策にはならないわけです。
補足
- 画像が表示されるとすぐに大半の要素は破棄されるため、これだけでも
Columnよりはマシです。 - 画像未表示でも高さが確保される一覧であっても、メモリの観点で
Columnは避けたほうが良いです。 GridViewは main axis 方向の要素サイズがアスペクト比と cross axis の指定個数で決まるので、未表示でもサイズが勝手に確保されると思います。
確実な対策
高さがないことが問題なので、それを設定すれば解決できます。
※実際には画像がなくてもテキストやらボタンやらで幾らか高さがあることが多いので、問題にはなりにくいです。画像ビューアのような画像メインの一覧では要注意です。
高さ指定① - 固定値
画像ぴったりの高さ(横スクロールなら幅)をあらかじめ設定して確保しておく方法です。
設定する対象は画像でも要素のアイテムでもいいですが、ここでは画像のほうに設定してみます。
ListView( cacheExtent: 0.0, children: [ for (var i = 0; i < 20; i++) ...[ SizedBox( // 画像の高さを指定 height: 100.0, child: Image.network('https://xxxxx.xxx/$i.jpg'), ), const Divider(), ], ], )

画像が未表示でも 100.0 の高さが確保されました。
見えている要素は三つで、読み込みも三枚に抑えられていることが DevTools でわかります。

また、メモリ使用量の変化も Column のときと全然違うのがわかります。
最初に一気に増えずに、読み込んだ画像とスクロールして見えなくなった画像によって増減しています。

このように ListView を使うのは転送量を抑えるだけでなくメモリ不足を防ぐことにもなります。
ListView と ListView.builder の違い
どちらも遅延の効果があります。
遅延というのは、表示部分+α の範囲に入るまで使われないことです。
その範囲に入ったときに初めて initState() が呼ばれ、範囲から外れれば dispose() が呼ばれます。4
そこは共通していて、違いはインスタンス生成のタイミングにあります。
デフォルトコンストラクタでは子 widget の List を children に直に渡すため、その時点かそれより前に生成することになります。
しかし生成しただけでは build() が呼ばれないどころか createState() も呼ばれないので、デフォルトコンストラクタでも画像読み込みを遅延させる効果があります。
全要素が先に生成される分 ListView.builder より少し多めにメモリが使用されますが、インスタンスのサイズだけなので小さいです。
パフォーマンスの面では、生成時のコストが高ければ ListView.builder のほうが好ましいです。
通常の利用ではどちらでも良いですが、ここから先は ListView.builder のほうを使っていきます。
要素のインデックスを受け取って生成に利用できるという使いやすさもあります。
高さ指定② - 最小値
①の指定方法は画像の高さが 100.0 だとわかっているので使えましたが、あらかじめわからなくて特定の固定サイズに拡大/縮小したくもない場合には SizedBox は適していません。
大量の読み込みを防ぐにはある程度の高さがあればいいので、画像より小さめの高さ(でもそれなりのサイズ)を最小値として設定しておけば OK です。
ListView.builder( cacheExtent: 0.0, itemCount: 20, itemBuilder: (context, index) { return ConstrainedBox( constraints: const BoxConstraints(minHeight: 50.0), child: Column( children: [ Image.network('https://xxxxx.xxx/$index.jpg'), const Divider(), ], ), ); }, )

画像の読み込みが終わっていない間のスクリーンショットです。
画像の高さ(100.0)よりは小さい(50.0)ので本来の表示数より多くなりますが、表示範囲に大量の要素が入ることは防げています。
また最小値しか指定していないので、その高さより画像が大きければ最小値に影響されずに最終的にちゃんと画像サイズで表示されます。

DevTools で効果が確認できました。
プレースホルダ画像
ListView.builder( itemCount: 20, itemBuilder: (context, index) { return Column( children: [ FadeInImage.assetNetwork( placeholder: 'images/placeholder.jpg', image: 'https://xxxxx.xxx/$index.jpg', ), const Divider(), ], ); }, )
読み込まれるまでの間に代わりのプレースホルダ画像を表示しておけば、高さがあるので大丈夫…
と思ってしまいそうですが、代わりを指定するだけではダメです。
プレースホルダ画像もローカルかどこかにあって非同期に読み込まれるので、その画像を読み込み終える前の一瞬は高さがない状態になってしまいます。
FadeInImage(や名前付きコンストラクタ)には height の引数があってそこで指定できますが、これはプレースホルダ画像と本来の画像の両方で使われる高さなので、どちらも指定の高さになってしまいます。
つまり①の方法と同じ意味になります。
FadeInImage.assetNetwork( height: 100.0, placeholder: 'images/placeholder.jpg', image: 'https://xxxxx.xxx/$index.jpg', )
ネットワークから取得する画像のサイズはわからない場合は、②の方法と併用してプレースホルダの高さを最小値として確保しましょう。
高さ指定③ - itemExtent
高さ指定①では画像の高さを固定しましたが、ListView の itemExtent を使って一覧のアイテムの高さを固定する方法もあります。
ListView( cacheExtent: 0.0, // 各アイテムの高さを100.0に統一 itemExtent: 100.0, children: [ for (var i = 0; i < 20; i++) ...[ child: Image.network('https://xxxxx.xxx/$i.jpg'), const Divider(), ], ], )
こうすれば画像が表示されていなくてもアイテムが 100.0 の高さになり、読み込み前に全アイテムが画面内に入ってしまうことを防げます。
ただし画像がその高さよりも大きいと overflow するので、FittedBox などで防ぐ必要があります。
また、全アイテムが同じ高さに統一されることがデザイン等の都合で許容できなければ使えません。
そのような制限がない②の方法のほうが広く対応できます。
ListView + 他の widget
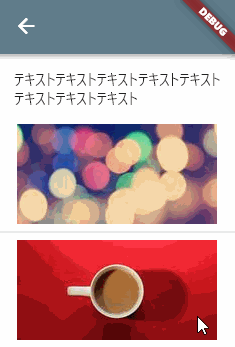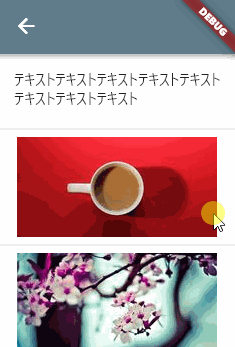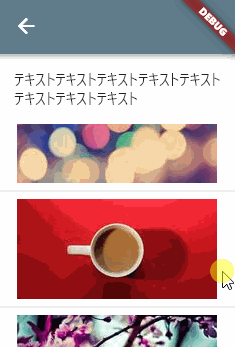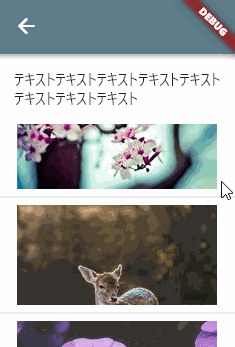
画面の上方に説明文などがあって、その下に一覧がある UI です。
一覧のみがスクロール対象です。
Column( children: [ Padding( padding: const EdgeInsets.all(16.0), child: Text('テキスト' * 8), ), Flexible( child: ListView.builder( itemCount: 20, itemBuilder: (context, index) { return Column( children: [ SizedBox( height: 100.0, child: Image.network('https://xxxxx.xxx/$index.jpg'), ), const Divider(), ], ); }, ), ), ], )
これはこれでいいのですが、AppBar 以外の全体をスクロールしたいこともあると思います。
その実装として、次のようなコードに最近出くわしました。
SingleChildScrollView( child: Column( children: [ Padding( padding: const EdgeInsets.all(16.0), child: Text('テキスト' * 8), ), ListView.builder( physics: const NeverScrollableScrollPhysics(), shrinkWrap: true, itemCount: 20, itemBuilder: (context, index) { return Column( children: [ SizedBox( height: 100.0, child: Image.network('https://xxxxx.xxx/$index.jpg'), ), const Divider(), ], ); }, ), ], ), )
SingleChildScrollView の中で ListView.builder を使い、scrollable なものが二重になるので、内側のほうを physics: NeverScrollableScrollPhysics() で non-scrollable にするという力技です。
「何だこれは!?」と思ってウェブ検索すると、その方法を紹介している記事がありました。
経験が浅い人ならそういう記事を読んでも悪手だと気づけずに信じてしまうので怖いですね。
なぜ悪手かというと、SingleChildScrollView + Column とほとんど変わらないことになるからです。
画像の読み込みが一気に起こってしまいます。
まとめてスクロール① - 地道な方法
代わりの方法の一つは、テキストの部分を ListView の先頭要素とする方法です。
おすすめはしないけれど一応使えます。
ListView.builder( // テキスト分として一つ増やしておく itemCount: 21, itemBuilder: (context, index) { return Column( children: [ if (index == 0) // テキストの部分をListViewの先頭要素として表示 Padding( padding: const EdgeInsets.all(16.0), child: Text('テキスト' * 8), ) else ...[ SizedBox( height: 100.0, // 一つ増やした分indexがずれるので差し引く child: Image.network('https://xxxxx.xxx/${index - 1}.jpg'), ), const Divider(), ], ], ); }, )
index がずれるので、本来の一覧部分でその index を使うときに間違えないようにしましょう。
なお、この方法は GridView には使えません。
GridView は基本的に cross axis の要素数を 2 以上にして使うので、テキストをその先頭にするとグリッドの一つとして狭い表示になってしまいます。
まとめてスクロール② - sliver
もっと Flutter らしいのは sliver 系の widget を使う方法です。
ListView や GridView も内部で sliver が使われているのですが、自分で直接使うなら細かな実装が必要で、そのための widget が多数あるので、難しい印象を受ける人が多いようです。
小難しい名前のクラスやメソッドもあります。
SliverOverlapInjector(handle: NestedScrollView.sliverOverlapAbsorberHandleFor(context))
などは確かに「はぁ?」と思いますね。
でもまとめてスクロールする程度なら難しいことはありません。
先に公式の動画を見たほうが理解しやすくなると思います。
Sliver の意味
英語の発音は /slívə(r)/ です。
細切れや薄切りにした一片のことで、Flutter ではスクロール部分の中の断片的な各パーツのことです。
それらのパーツをまとめて一繋がりに scrollable にしたり、もっと高度なスクロール効果を実現できたりします。
意味がわかると抵抗感が少し減るんじゃないでしょうか。
Sliver を使ってみる
CustomScrollView( slivers: [ SliverToBoxAdapter( child: Padding( padding: const EdgeInsets.all(16.0), child: Text('テキスト' * 8), ), ), SliverList( delegate: SliverChildBuilderDelegate( (context, index) { return Column( children: [ SizedBox( height: 100.0, child: Image.network('https://xxxxx.xxx/$index.jpg'), ), const Divider(), ], ); }, childCount: 20, ), ), ], )
長い部分を省略して書くと下記のように意外とシンプルです。
複数の子を持つ ListView と似た構造ですね。
テキスト部分とその下の一覧の計二つをスクロール内の断片(slivers)として持っています。
CustomScrollView( cacheExtent: 0.0, slivers: [ // テキストの部分 SliverToBoxAdapter(child: ...), // テキストの下の一覧 SliverList(delegate: ...), ], )
- 一般的に
CustomScrollViewが使われるScrollViewの一種で、sliver 系の widget を組み合わせて様々なスクロールの効果を作るのに使える- 他に
BoxScrollViewがあり、ListViewとGridViewはそれを継承している
sliversには sliver 系の widget しか渡せないcacheExtentはSliverListではなくCustomScrollViewのほうで設定
ではコードの省略を少し減らして再度見てみましょう。
CustomScrollView( slivers: [ // テキストの部分 SliverToBoxAdapter( child: ..., ), // テキストの下の一覧 SliverList( delegate: SliverChildBuilderDelegate( (context, index) => ..., childCount: 20, ), ), ], )
SliverList の delegate に渡すものは、SliverChildListDelegate が ListView のデフォルトコンストラクタ、SliverChildBuilderDelegate が ListView.builder に近いです。
この例では後者を使いました。

テキストと一覧を一緒にスクロールすることを可能にしつつ、ListView と同様の遅延も実現できました。
余白を設ける
SliverSizedBox という widget は存在しないので SliverToBoxAdapter と SizedBox を組み合わせないといけません。
CustomScrollView( slivers: [ ..., const SliverToBoxAdapter( child: SizedBox(height: 16.0), ), ..., ], )
SliverPadding も使えます。
子を指定する引数が child ではなくて sliver になっていて便利です。
これを使って SliverList の周りに padding を付けても画像の遅延読み込みに悪影響しません(確認済み)。
SliverPadding( padding: const EdgeInsets.all(16.0), sliver: SliverList(...), )
sliver についてもっと詳しく知りたい場合は下記記事が参考になると思います。
公式ドキュメント からもリンクされています。
ローカルにキャッシュする
遅延読み込みと併用しておきたいのがキャッシュです。
画像が頻繁に変わるならキャッシュの有効期間が短くて効果が薄いですが、高頻度で変わるアプリが多いとは思えないので使えるケースのほうが多いと思います。
メリットとデメリット
- バックエンドからの転送量を減らせる
- 費用に影響しない
- ユーザの通信量も減る
- 大量に読み込んでもサーバの負荷にならない
- 表示速度が上がる
といったメリットがあります。
デバイス上のストレージは使用量が増えますが、デメリットというほどではないと思います。
無制限にキャッシュしてしまうアプリを使って空き容量がゼロになった経験はありますが…。
そんな酷いアプリにならないように、パッケージでキャッシュの期限などを設定できます。
パッケージを使わなくてもアプリが起動している間はある程度キャッシュされるようですが、再起動してもキャッシュが残るようにするにはプラグインパッケージが必要です。
cached_network_image
記事を書くにあたって探し直したのですが、過去にあったパッケージが discontinued になっていたり、人気が高めのパッケージでもテストコードがなかったりしました。
費用に関わる重要なところなので、自動テストされていないようなパッケージは選定対象になりません。
安心して使えそうなのは cached_network_image くらいでした。
他に同等の機能と人気/安定性を持つパッケージがあればぜひ教えてください。
このパッケージは公式の Cookbook でも紹介されていますが、細かな制御の説明はありません。
でも先に読むと良いと思います。とても短いです。
これまで何度か使っているのですが、細かい設定までしたことがなかったので調べてみました。
ドキュメントから読み取ったことくらいしか書かないので、使うときにご自分で読んだり試したりしてください。
対応プラットフォーム
パッケージのページでは Android、iOS、macOS のみの表記になっていますが、下記 issue 内の情報によれば他のプラットフォームでも動くようです。
キャッシュ制御設定の例
内部で flutter_cache_manager というパッケージが利用されていて、そちらの機能で制御できるようになっているようです。
下記はそのパッケージのページに載っている例です。
class CustomCacheManager { static const key = 'customCacheKey'; static CacheManager instance = CacheManager( Config( key, stalePeriod: const Duration(days: 7), maxNrOfCacheObjects: 20, repo: JsonCacheInfoRepository(databaseName: key), fileSystem: IOFileSystem(key), fileService: HttpFileService(), ), ); }
有効な期間(stalePeriod: どれだけ経っていればもう古いとみなすか)やキャッシュの数(maxNrOfCacheObject) が指定されています。
こうやって設定すれば無制限にキャッシュしてしまうことはなくなりますね。
Config の引数
IOFileSystem は flutter_cache_manager パッケージ内の export されていないファイルに書かれています。
ユーザが直接利用できないのでどうすればいいか調べてみると、Config は抽象クラスになっていてプラットフォーム別に実装されていました。
例えばウェブ以外用の実装クラスでは下のスクリーンショットのようになっています。

fileSystem に何も渡されなければ IOFileSystem が使われるようになっていますね。
ウェブなら MemoryCacheSystem です。
repo・fileSystem・fileService の三つは省略しておけば良さそうです。
デフォルトのキャッシュ設定
上のスクリーンショットの Config の実装は DefaultCacheManager でも使用されているので、自分で cacheManager を指定しないときのデフォルト設定になります。
有効期間 30 日、最大数 200 のままでいいなら省略で OK です。
CacheManager のインスタンス
The cache manager is customizable by creating a new CacheManager. It is very important to not create more than 1 CacheManager instance with the same key as these bite each other. In the example down here the manager is created as a Singleton, but you could also use for example Provider to Provide a CacheManager on the top level of your app. Below is an example with other settings for the maximum age of files, maximum number of objects and a custom FileService. The key parameter in the constructor is mandatory, all other variables are optional.
CacheManager のインスタンスは一つのキーにつき一つだけにしないといけないようです。
Singleton パターンを使うか、一つを用意して DI して使い回せば大丈夫です。
CachedNetworkImage で使うには、DI 等で受け取ったインスタンスを cacheManager という引数に渡します。
特定の画面で表示する画像は長期間のキャッシュを主に使い、他の画面では短期間にしておきたいような場合、異なるキーで CacheManager を用意しておいて使い分ければいいんじゃないかと思います。
保存先
By default the cached files are stored in the temporary directory of the app. This means the OS can delete the files any time.
Information about the files is stored in a database using sqflite on Android, iOS and macOs, or in a plain JSON file on other platforms. The file name of the database is the key of the cacheManager, that's why that has to be unique.
デフォルトでは、ファイルはアプリの一時ディレクトリにキャッシュされ、その情報は Android・iOS・macOS では sqflite、他プラットフォームではプレーンな JSON ファイルに保存されるそうです。
また、一時ディレクトリなのでそこのファイルは OS によって消されることがあるとのことです。
キャッシュがなくなることがあって再びダウンロードが起こりますよ、という意味だと私は理解しました。
消えているかどうかを確認しながら使わないといけないという意味ではないと思いますが、未確認です。
画像が更新された場合
A valid url response should contain a Cache-Control header.
flutter_cache_manager は HTTP の Cache-Control ヘッダに従うようです。
画像配信側で適切に設定していないと意図した動作になりません。
- キャッシュさせない設定になっていると、キャッシュ用のパッケージを使っても意味がない
- 再検証までの期間が長めに設定されていると、画像を更新してもクライアント側でキャッシュを使ってしまう
といったことが考えられます。
キャッシュ期間を長くして再検証までの期間を短くするのが良さそうです。
画像ファイル名
ファイル名も重要です。
例えば商品一覧に coffee.png という画像を表示しているとすると、キャッシュ期間内に更新されたときに名前が同じならキャッシュが使われますが、coffee2.png に変えて一覧データ内に含まれるファイル名も変えればキャッシュを無視できます。
大きな画像のキャッシュ
キャッシュしても画像が大きければメモリが多く使用されます。
あらかじめ縮小しておく(大きく表示したい箇所以外では縮小済みの画像を使う)のが良いですが、クラウドのストレージに縮小画像がない場合などにローカルでキャッシュ画像のサイズを小さくすれば、何もしない場合より使用量を抑えることができるはずです。
- maxWidthDiskCache / maxHeightDiskCache
- 画像を縮小してディスクキャッシュに保存する
- memCacheWidth / memCacheHeight
ResizeImageを使ってメモリ上の画像を縮小する
試してはいないので効果を確認したわけではないのですが、Flutter 標準の Image.xxx(Image.network など)にある cacheWidth / cacheHeight に近いものだと思われるので、おそらく使用メモリの削減になります。
まとめ
遅延読み込み、メモリ使用量抑制
ColumnやRowを避けるListViewやGridViewを使う 5
- 高さ(横スクロールなら幅)の確保が必要
- プレースホルダ画像を使ってもサイズ指定は必要
SingleChildScrollView+ListView/GridViewはダメ- sliver を使う
キャッシュ
- 積極的に使う
- パッケージは
cached_network_image - 適切に設定しないと意図しない挙動になり得る
これらとサムネイル画像の使用(+ 場合によってはパジネーションなども)を組み合わせましょう。
-
Lorem Picsum からダウンロードして使いました。そのサイトの画像に直接的に大量アクセスすると悪影響を与えかねないので、ローカルのウェブサーバを使っています。ご自分で試したい方はご注意ください。↩
-
maximumSizeとmaximumSizeBytesは0をセットしたときにキャッシュがクリアされるので、どちらかに0を設定してから元の値に戻すという意図的な消去にも使えます。↩ -
cacheExtentのデフォルト値は250.0です。↩ -
要素が破棄されても、その中で使われていた画像はキャッシュされていて次の表示時にダウンロードし直さずに使えるようです(ただしアプリを終了したら消えます)。無限にキャッシュされるかどうかは把握していません。↩
-
ListView(おそらくGridViewも)には難点があるので注意しましょう。FormFieldを使っている要素が見える部分 +α の範囲から外れるとバリデーションが効かないそうです(https://github.com/flutter/flutter/issues/56159)。外れたときに dispose される仕組みが影響しているとすれば、不具合というよりは仕様に思えます。↩
Freezedの代替方法を考える(Immutability編)
前編では、同一性を判定できる機能を Freezed を使わずにクラスに持たせる方法を確認しました。
今回は immutability です。
前回は equatable を使うだけでできるという仮定で検証作業ばかりだったのですが、今回はいくつかの方法を試して比較しつつデメリットも考えて結論を出します。
何もしない場合
Equatable クラスには @immutable のアノテーションが付いているので、それを継承したクラスでもすべてのプロパティを final にしなければならず、プロパティに値を代入し直すことができません。
したがって、次のようにプロパティの値が丸ごと差し替えられるのを防ぐことができます。
final list1 = MyList([1, 2, 3]); list1.list = [1, 20, 3]; // エラーになる
しかし、コレクションのプロパティが final であっても中身の変更はできてしまいます。
final list1 = MyList([1, 2, 3]); list1.list[1] = 20; print(list1.list); // [1, 20, 3]
また、別の変数に入れてからいじると元の変数にまで影響します。
final list1 = MyList([1, 2, 3]); final copiedList = list1; copiedList.list[1] = 20; print(list1.list); // [1, 20, 3]
次のように private にしてゲッターで List を返すようにしても効果はありません。
class MyList extends Equatable { const MyList(List<int> list) : _list = list; final List<int> _list; List<int> get list => _list; @override List<Object> get props => [_list]; } ... final list1 = MyList([1, 2, 3]); list1.list[1] = 20; print(list1.list); // [1, 20, 3]
Freezed に関する勘違い
調査にあたり Freezed における immutability の実現方法も調べていたのですが、生成されたコードを見てもそれらしき記述が見当たりませんでした。
それでも自分の見落としだと思って調べ続けた結果、判明しました。
Freezed はあまり immutable じゃない!
Freezed を使えば先ほどのようなコレクションの問題は起きないと思い込んでいました。
「あまり」immutable じゃないと書きましたが、コレクションに限れば「全然」です。
@freezed class MyFreezedList with _$MyFreezedList { const factory MyFreezedList(List<int> list) = _MyFreezedList; }
これを生成元として Freezed でクラスを生成して試します。
コレクションを変更できてしまう!
final l = [1, 2, 3]; final freezedList = MyFreezedList(l); l[1] = 20; print(freezedList.list); // [1, 20, 3]
元の List の値を変えると、オブジェクトで持っている List まで変わってしまいました。
freezedList.list[2] = 30; print(l); // [1, 20, 30]
逆にオブジェクト側の List をいじっても元の List に影響しました。
Flutter で StateNotifier を使う場合も同じです。
下記のように StateNotifier で管理する state が List を持っているとき、select() でその List を取り出してから中身を変更することができ、その変更は state 内の List にも元の List にも影響します。
@freezed class MyListState with _$MyListState { const factory MyListState(List<int> list) = _MyListState; } class MyListNotifier extends StateNotifier<MyListState> { MyListNotifier({required List<int> list}) : super(MyListState(list)); }
final originalList = [1, 2, 3]; ... StateNotifierProvider<MyListNotifier, MyListState>( create: (context) => MyListNotifier(list: originalList), child: MaterialApp(home: ...), ) ... final list = context.select((MyListState state) => state.list); list[1] = 20; // 関連する全てのListに影響 print(list); // [1, 20, 3] print(context.read<MyListState>().list); // [1, 20, 3] print(originalList); // [1, 20, 3]
ディープコピーもしてくれない!
final freezedList1 = MyFreezedList([1, 2, 3]); final freezedList2 = freezedList1.copyWith(); freezedList2.list[2] = 20; print(freezedList1.list); // [1, 20, 3]
コピーして作ったオブジェクトの List をいじると、コピー元のオブジェクト内の List に影響しました。
これでは全く対策されていないのと同じですね。
Freezed の immutability の機能を推すツイートや記事が散見されていたのですが、何だったのでしょう。
build_collection + built_value の上位種みたいなものじゃなかったのでしょうか…。
なお、作者はコレクションを immutable にするつもりがないようです(issue)。1
ディープコピーについては 提案 が出ています。
Freezed と同等の immutability を実現するには
Freezed の immutability の機能が今見た程度であれば、それと同等にするのは簡単です。
- クラスに
@immutableのアノテーションを付けてほぼ強制的に各プロパティをfinalにさせる @immutableを自分で付けなくてもEquatableに付いているので、それを継承すればいい- プロパティの値を変更できない代わりとして
copyWith()が必要だが、自作は難しくない
Freezed と同等で良い方はここまでで OK です。
どこまで堅牢にするか
コレクションを操作しないルールにするだけで解決するチーム環境ではそれでいいと思います。
しかし、世の中には想定を超えることをしてしまう人や、レビュー等で何度伝えてもできない人もいます。
そういう環境に入ったことがない方には理解しがたいかもしれませんが…。
コード面でどこまで対策をしておくかは手間等と効果のバランス次第ですが、間違った方法を使おうとしてもできないようにするのは、これまでの経験から重要に感じています。
そのように不安を少しでも減らしておきたい方はこの先を参考にしてください。
コレクションも immutable にする
immutability の実現方法は一つではありません。
- オブジェクト内のコレクション自体が unmodifiable
- mutable だけれど別の変数に入れていじってもオブジェクト内のコレクションに影響しない
一長一短がありますので、それぞれの方法を見ながらデメリットも考えます。
① コレクションを unmodifiable 化
- List.unmodifiable / Map.unmodifiable / Set.unmodifiable
dart:collectionの UnmodifiableListView / UnmodifiableMapView / UnmodifiableSetView
これらを使うとコレクションの一階層目を unmodifiable(変更不可)にするのが簡単にできます。
まず二種類の違いを確認しましょう。
List.unmodifiable と UnmodifiableListView
下記のようにすると、どちらの方法でも変更不可になります。
残念ながらエラーは静的解析で検出されずにランタイムに起こりますので、その点はちょっと使いにくいです。
final list = [1, 2, 3]; final unmodifiableList1 = List.unmodifiable(list); final unmodifiableList2 = UnmodifiableListView(list); unmodifiableList1[1] = 20; // エラー(Cannot modify an unmodifiable list) unmodifiableList2[2] = 30; // エラー(Cannot modify an unmodifiable list)
こう見ると List.unmodifiable と UnmodifiableListView の違いがわからないのですが、
次のように元 List を変更してみるとわかります。
final list = [1, 2, 3]; final unmodifiableList1 = List.unmodifiable(list); final unmodifiableList2 = UnmodifiableListView(list); list[1] = 20; print(unmodifiableList1); // [1, 2, 3] print(unmodifiableList2); // [1, 20, 3]
UnmodifiableListView のほうは元の List の変更が影響する結果になりました。
その理由はドキュメントには(Dart 2.12.4 時点では)書かれていませんが、
こちらの記事
で解説されています。
may perform a bit better, because an UnmodifiableListView does not create a copy of the original list. Instead, it wraps the original in a view that prevents modification.
https://dart.academy/immutable-data-patterns-in-dart-and-flutter/
UnmodifiableListView のほうは元 List をコピーしない(のでパフォーマンスが少し良い)ということです。
コピーせずに元の List をラップして使っているので影響してしまうわけですね。
UnmodifiableMapView と UnmodifiableSetView もコピーしないのか
final map = {'a': 1, 'b': 2, 'c': 3}; final unmodifiableMap1 = Map.unmodifiable(map); final unmodifiableMap2 = UnmodifiableMapView(map); // 元の Map の中身を変更 map['b'] = 20; print(unmodifiableMap1); // {a: 1, b: 2, c: 3} print(unmodifiableMap2); // {a: 1, b: 20, c: 3}
final set = {1, 2, 3}; final unmodifiableSet1 = Set.unmodifiable(set); final unmodifiableSet2 = UnmodifiableSetView(set); // 元の Set に要素を追加 set.add(4); print(unmodifiableSet1); // [1, 2, 3] print(unmodifiableSet2); // [1, 2, 3, 4]
UnmodifiableListView と同様にやはり UnmodifiableMapView と UnmodifiableSetView もコピーしない仕組みになっているようです。
ちなみに、Set.unmodifiable と UnmodifiableSetView は Dart 2.12 で追加されたばかりの新しい機能だそうです。
どちらを使うか
UnmodifiableXxxView で元のコレクションに加えた変更が影響することは危険な場合がありますね。
それを考慮すると、選択肢は
- 影響するのは怖いので
List.unmodifiableを使う(パフォーマンスが少し劣るのは許容する) - 元のコレクションをいじらないよう自分で注意しながら
UnmodifiableListViewを使う(パフォーマンスを優先)
の二択になります。
使用箇所のパフォーマンスの重要性などに応じて決めましょう。
変更できなくなるのは一階層のみ
Xxx.unmodifiable と UnmodifiableXxxView はどちらも深い階層までまとめて変更不可にしてくれません。
final list = [[1, 2], [3, 4]]; final unmodifiableList1 = List<List<int>>.unmodifiable(list); final unmodifiableList2 = UnmodifiableListView(list); unmodifiableList1[0][1] = 20; unmodifiableList2[0][3] = 40; print(unmodifiableList1); // [[1, 20], [3, 40]] print(unmodifiableList2); // [[1, 20], [3, 40]]
内側の List は変更が反映されました。
また、次のように元の List で深い層をいじった場合も影響します。
final list = [[1, 2], [3, 4]]; final unmodifiableList1 = List<List<int>>.unmodifiable(list); final unmodifiableList2 = UnmodifiableListView(list); list[0][1] = 20; print(unmodifiableList1); // [[1, 20], [3, 4]] print(unmodifiableList2); // [[1, 20], [3, 4]]
実装(一階層のみ unmodifiable)
深い階層まで変更不可にする前に一階層用の実装をしてみましょう。
unmodifiable にするとき、(内部処理は未確認ですが)何らかの変換が行われていると仮定します。
オブジェクトからコレクションを取り出すときに毎回その変換が起こるのは無駄がありますし、
大きなコレクションでは変換が終わるまで待たされることが問題になるかもしれません。2
そのコストを考慮し、初期化リストでの一度の変換で済むようにします。
class MyUnmodifiableList extends Equatable { MyUnmodifiableList(List<int> list) : list = List.unmodifiable(list); final List<int> list; @override List<Object> get props => [list]; } ... final unmodifiableList = MyUnmodifiableList([1, 2, 3]); unmodifiableList.list[1] = 20; // エラー(Cannot modify an unmodifiable list)
Dart 2.12 で導入された late キーワードを活用すればコンストラクタで行うこともできます。
MyUnmodifiableList(List<int> list) { this.list = List.unmodifiable(list); } late final List<int> list;
オブジェクトからコレクションを取り出すたびに変換が起こるのを気にしなくていい場合には、コレクションのプロパティを private にしてゲッターで公開し、そのゲッターで返すときに変換すればいいと思います。
実装(深い階層まで unmodifiable)
深い階層まで対応させるのは、コレクションの中身すべてに unmodifiable を適用していくだけです。
例えば二次元の List なら下記のようになります。
class NestedList extends Equatable { NestedList(List<List<int>> list) : list = List.unmodifiable(list.map<List<int>>( (v) => List<int>.unmodifiable(v), )); final List<List<int>> list; @override List<Object> get props => [list]; } ... final nestedList = NestedList([[1, 2], [3, 4]]); nestedList.list[0] = [20]; // エラー(Cannot modify an unmodifiable list) nestedList.list[0][1] = 20; // エラー(Cannot modify an unmodifiable list)
.map() でイテレートしながら内側まで unmodifiable にしています。
Map の中に Map があってその中に List があるような複雑な構造でも意外と簡単で、これもやはり
.map() を使って隈なく unmodifiable を適用していくだけです。
class ComplexCollection extends Equatable { ComplexCollection(Map<String, Map<String, List<int>>> map) { this.map = Map.unmodifiable(map).map((k, v) { return MapEntry(k, Map.unmodifiable(v).map((k, v) { return MapEntry(k, List.unmodifiable(v)); })); }); } late final Map<String, Map<String, List<int>>> map; @override List<Object> get props => [map]; }
実際には、unmodifiable を使うときに Map<String, Map<String, List<int>>>.unmodifiable(...)
のようにジェネリック型を指定しないといけなくて長い記述になるので見づらくなります。
この読みにくさの問題は実用の判断に影響しそうです。
UnmodifiableXxxView のほうはジェネリック型の指定が不要なので、多少すっきりした記述になります。
unmodifiable のデメリット
ここまで unmodifiable にする方法を見ました。
そうやって変更できなくするのは安全に思えるのですが、使うときに不便なこともあります。
例えば Flutter で StateNotifier を使うとき、それを継承したクラスで管理する state は immutable である前提なので、
state が持つ値を変えたいときにはプロパティの値を直接変更できません。
代わりに Freezed で state のクラスを作ってその copyWith() で新たな state オブジェクトを作るスタイルが一般的です。
もし state がコレクションのプロパティを持っていてその一部を変更した状態にしたければ、
次のようにコレクションを取り出して一部だけを変えたものを copyWith() に渡せばできます。
final list = state.list; list[0] = 'newValue'; state = state.copyWith(list: list);
それに対し、コレクションを unmodifiable にする方法では部分的な変更が不可能なので再利用できません。
再利用したいケースでは実質的に次の方法に絞られます。
② ディープコピーによって影響を及ぼさなくする方法
unmodifiable にしないまま immutability を実現する方法です。
immutable と unmodifiable という言葉の区別はちょっと難しいですね。
先にそこをはっきりさせておきましょう。
immutable と unmodifiable
前者は 「変わらない」こと、後者は「変更できない」ことを表していると思います。
List.unmodifiable が List.immutable という名前でないのは、
おそらくコレクションが「変更できない」ことを明確にするためです。
unmodifiable であれば immutable になりますので、immutability のための方法の一つとして unmodifiable にする方法がある、という関係性です。
- オブジェクトが持つ値を全く変更できない(unmodifiable)
- オブジェクトから取り出した値を変更できるが、オブジェクトが保持する値に影響しない
オブジェクトの immutability を「変わらない/不変」という言葉と照らして考えると、次のどちらも immutable だと言えると思います。
では、後者のほうをこれから見ていきます。
ディープコピー
先ほどごちゃごちゃと unmodifiable の方法を書いておきながらアレなのですが、この方法でいいと思います。
楽かつ使いやすいです。
Map<String, Map<String, List<int>>> という深めの階層構造であっても、次のように割と簡潔に書けます。
final copiedMap = originalMap.map((k, v) { return MapEntry(k, v.map((k, v) { return MapEntry(k, v.map((v) { return v; }).toList()); })); });
または、少し楽をして一番内側だけ List.of() や Map.of() で済ませます。
final copiedMap = originalMap.map((k, v) { return MapEntry(k, v.map((k, v) { return MapEntry(k, List.of(v)); })); });
.map() を使ってコレクションの一番内側までイテレートしながら新たな MapEntry を作っていくのは先ほどと同じですが、
Map.unmodifiable 等による変換がないのでシンプルです。
記述しやすくて読みやすいだけでなく、変換がなくてイテレーションのコストだけで済むのも良いです。
これをクラスに組み込む方法については、
- 初期化リストかコンストラクタでディープコピーを用意する場合
- 元のコレクションが変更されても影響を受けない
- オブジェクトから取り出したコレクションが変更されると影響を受ける
- ゲッターで返すときにディープコピーする場合
- 元のコレクションが変更されると影響を受ける
- ゲッターで返したコレクションが変更されても影響を受けない
となります。
外部での操作による影響を完全に受けなくするには、両方のタイミングでコピーしないといけません。
下記のコードでは一応両方でコピーするようにしました。
どこまで厳密にやるかはご自身で判断してください。
class ComplexCollection2 extends Equatable { ComplexCollection2(Map<String, Map<String, List<int>>> map) { _map = _deepCopy(map); } late final Map<String, Map<String, List<int>>> _map; Map<String, Map<String, List<int>>> get map => _deepCopy(_map); @override List<Object> get props => [_map]; Map<String, Map<String, List<int>>> _deepCopy( Map<String, Map<String, List<int>>> originalMap, ) { return originalMap.map((k, v) { return MapEntry(k, v.map((k, v) { return MapEntry(k, List.of(v)); })); }); } }
ディープコピーのメソッドは各クラスに書いてもいいのですが、複数のクラスで同じ型が使われている場合には、 流用できるように static なメソッドにでもしておくといいかもしれません。
また、長い型名が何度も書かれているのをどうにかしたい感じがありますが、もうすぐ導入されそうな 型エイリアス (関数以外の型にも使えるエイリアス)で短い名前への置き換えが可能になるはずです。
ディープコピーのもう一つの方法
ディープコピーするには、JSON に変換してから戻す方法もあります。
この方法も考えたのですが、戻すと型が dynamic になってしまい、それを一気に Map<String, Map<String, List<int>>>
等にキャストすることはできないので、結局イテレートしながら一階層ずつキャストしないといけません。
また、先ほどの方法よりコストが少し大きそうなので、不採用としました。
参考に、JSON 形式を Map<String, Map<String, List<int>>> 型に変換するメソッドを書いておきます。
Map<String, Map<String, List<int>>> fromJson(Map<String, dynamic> json) { return json.map((k, dynamic v) { return MapEntry(k, (v as Map<String, dynamic>).map((k, dynamic v) { return MapEntry(k, (v as List).map((dynamic v) { return v as int; }).toList()); })); }); }
読みやすくするために改行を少なめにしていますが、フォーマットすると実際にはもっと改行が入って見た目が変わると思います。
もっと簡潔な方法があればぜひ教えてください。3
copyWith()
オブジェクトを immutable にするからには copyWith() メソッドもほぼ必須です。
難しいことは何もないのでさっと済ませます。
class Foo extends Equatable { const Foo({ required this.number, required this.text, this.isValid = false, }); final int number; final String text; final bool isValid; @override List<Object> get props => [number, text, isValid]; Foo copyWith({ int? number, String? text, bool? isValid, }) { return Foo( number: number ?? this.number, text: text ?? this.text, isValid: isValid ?? this.isValid, ); } }
自身と同じ型のオブジェクトを作り直すので、戻り値はクラスと同じ型です。
また、値を変えたいプロパティと同名の引数以外は省略可能にするために、仮引数の型はすべて nullable にします。
省略された引数は null であり、その場合は既存の値がそのまま設定されます。
null にする機能
Freezed で作った場合には null を設定するとプロパティの値を null にすることができますが、その機能は上記コードでは実現できません。
しかし、引数が指定されていないのか null が渡されたのかを区別できないのが Dart の仕様であり、Freezed を使った場合だけ異なるのは必ずしも良いとは限りません。
個人的には resetNumber() や nullifyNumber() のような説明的な名前のメソッドを作ってリセットできるようにするほうが明示できて良いと思います。
copyWith() を改良
コレクションの操作を失敗するタイミングの一つが copyWith() を使うときです。
class MyList { const MyList({this.list = const []}); final List<int> list; MyList copyWith({List<int>? list}) { return MyList(list: list ?? this.list); } } ... final originalList = [1, 2, 3]; final myList = MyList(list: originalList); final newList = myList.list; final myList2 = myList.copyWith(list: newList..add(4)); print(originalList); // [1, 2, 3, 4] print(myList2.list); // [1, 2, 3, 4]
このように元のコレクションに影響させてしまうミスです。
これを防ぐために、ディープコピー済みのコレクションを copyWith() 時に受け取って使えるようにするのはどうでしょうか。
区別するためにメソッド名を update() とします。
typedef ListUpdater<T> = List<T> Function(List<T>); ... MyList update({ListUpdater<int>? list}) { return MyList( list: list == null ? this.list : list(List.of(this.list)), ); } ... final myList2 = myList.update(list: (list) => list..add(4)); print(originalList); // [1, 2, 3] print(myList2.list); // [1, 2, 3, 4]
update() の引数を単なる List ではなく builder 関数にしました。
ここでは型を ListUpdater としましたが、わかりにくければ ListBuilder とか。
その builder に List が渡されるのですが、その List はディープコピー済みのものなので、上記のように直接 add() しても MyList 内の List や元の List に影響することがありません。
このように改良しても final newList = mylist.list; のように直接取り出すのを禁止するわけではないので確実な対策にはなりませんが、少しリスクを減らせます。
まとめ
二編全体のまとめです。
同一性を判定できるようにするには
Equatableを継承し、propsで全プロパティの List を返すようにするだけで OK
Freezed と同等の immutablity を実現するには
copyWith()を作るだけでいい- Freezed を使ってもコレクションは immutable にならない
Equatableが@immutableなので各プロパティは必然的にfinalになる
コレクションも immutable にするには
- 二つの方法がある
- unmodifiable にする方法
- ディープコピーで影響を受けなくする方法
- unmodifiable は少しコストがかかる可能性があり、使いにくくもなるため、ディープコピーがおすすめ
コレクション関連でやや手間がかかりますが、コレクションを持つクラスばかりではないと思いますので、一部のクラスだけちょっと面倒を我慢して作るだけならいいんじゃないでしょうか。
おまけ
Dart Data Class という Android Studio / IntelliJ IDEA 用のプラグインをうっきーさん @ukkey0518 が教えてくださいました。(ありがとうございます! ⇒ ツイート)
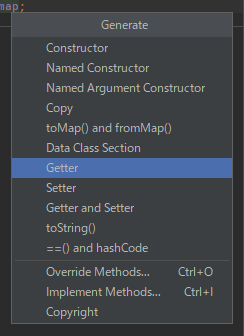
これもコード生成なのですが、同じファイルの対象クラス内に追記されますし、 Freezed で生成される読みにくいコードと違って手入力の代わりに自動で入力されたような普通のコードなので、 コンフリクトの解消がしやすそうです。
また、一瞬で生成されて体感が断然良いです。
高速なのは、一クラスずつ&機能単位の生成だからだと思います。
ただし
- 古い Dart を引きずっている(
newが付く、null safe じゃない、など) - Map と JSON との間の変換はキャストが甘すぎて使い物にならない
- プロジェクト全体分の生成をしたいときに大変そう
といった問題や制限があります。
ゲッターを追加、toString() を追加、のような個々の生成機能によってクラス作成を補助する程度には使えると思います。
「Data Class Section」を選ぶと複数の機能の追加をまとめて行えました。

VS Code でも検索すると類似のプラグインが複数出てきます。
また、JSON との変換などの特定機能に絞ったプラグインも IntelliJ と VS Code の両方にあります。
それらは試していませんが、もしかしたら上記プラグインより実用的かもしれません。
build_runner 系の生成しか頭になかったですが、build_runner を避けて別のツールを使うのもありですね。
意欲と技術力のある方は自分で Dart 等で変換ツールを作っても良さそうです。
-
この issue について「待ち」さん @freqmodu874 に教えていただきました。ありがとうございました! https://twitter.com/freqmodu874/status/1382891789204426752?s=20↩
-
UnmodifiableXxxViewのほうは元のコレクションのラップなので、変換のような処理ではなくコストが低い可能性もあります。↩ -
バックエンドとのやり取りに普段 gRPC を使っていて JSON の変換が不要なので不慣れです。gRPC はおすすめですよ(参考記事)。↩
Freezedの代替方法を考える(同一性判定編)
以前に考えていたときに試したコードなどが発掘されたので記事にすることにしました。
まず Freezed について
用途
Freezed は Dart のクラスの自作しにくい機能を自動生成によって楽に実現できるパッケージで、様々な機能があります。
- 同一性(Equality)の判定が可能(Equatability)
- 不変性(Immutability)
- copyWith()
- toString()
- Json とクラスオブジェクトの間の変換
- Union/Sealed クラス
以前は Dart 2.12 の一部機能(non-null, late)の先取りでもありましたが、今はこれくらいでしょうか。
こう見ると、どれも Freezed を使わずにできないこともないなと思います。
それでも Freezed を使うのは、自作に手間がかかるからです。
でも満足できていますか?
Freezed を使うことによる辛さもあるのではないでしょうか。
辛いところ
- 少し癖のある Freezed 用の書き方を把握しないといけない
- 元ファイルと同じ場所に生成されてフォルダ内/ファイルツリーがごちゃつく
- 生成するのに時間がかかる(build.yaml で対象ファイルを絞ったとしても)
- 生成後に Dart Analyze をやり直さないと生成前の解析状態のままになることが多い
- ブランチを切り替えるたびに生成&解析を行わないといけない(レビュー時など)
- 生成されたファイルを git の管理対象にすれば避けられるがコンフリクトが増える
- ちょっと変えて試したいときもいちいち生成&再解析が必要
- 生成用パッケージ(freezed, build_runner 等)の依存関係で悩むことがある
- もし生成用パッケージ側のエラーが出ればお手上げ
一部は Freezed ではなく build_runner が原因かもしれませんが、辛みがあることに変わりはありませんね。
楽をするために別の苦労が増えるのを好まない私は個人的には使っていません。
でも、業務になると別です。
自分の好みでなくても、チーム全員が簡単にできる方法が他にない限りは Freezed が採用されがちな現状です。
本記事について
書いた理由は、Freezed を使わない選択肢を広めることで私自身が苦痛から解放されたいからです。
好まないものを使うストレスは結構大きいものです。
このシリーズ(といってもおそらく二編)では、冒頭に書いた Freezed の用途のうち同一性と immutability(copyWith() のことも含む)に絞ります。
残りはたぶん気が向かない限り書きません。
まず今回は同一性を判定できるようにする方法です。
先に言ってしまうと、第一編は package:equatable の機能を検証していくだけなので割としょうもないです。
同一性(Equality)
同一性(同値性)を判定できる機能をクラスに持たせるのは == と hashCode をオーバーライドして実装するだけでできるので、自作するのも難しくありません。
でもコレクションの同一性はちょっと難しいです。
final list1 = [1, 2, 3]; final list2 = [1, 2, 3]; print(list1 == list2); // false
同じ値が同じ順序で入っている List であっても、等価演算子(==)で比較すると false になります。
比較処理を自力で実装するなら for などを使って要素を一つずつ比較することになります。
その手間を省ける方法として package:collection に含まれる
DeepCollectionEquality が使えます。1
さらに、それを利用している package:equatable があります。
この記事では equatable のほうを使います。
equatable パッケージ
状態管理のメジャーなパッケージの一つである flutter_bloc の作者が作ったものです。
安心感がありますね。
まずはコレクションではなく String のプロパティを持つクラスを例に見てみましょう。
equatable を使わない場合
class Person { const Person(this.name); final String name; } ... final taro1 = Person('Taro'); final taro2 = Person('Taro'); print(taro1 == taro2); // false
name の値が同じオブジェクトを二つ作って比較しても false になります。
※const を付けるとコンパイル時に用意され、使い回されて結果に影響してしまうため、
この記事の検証ではあえて付けないようにしています。
equatable を使う場合
同じ値が同一と判定されるようにするために equatable を使うと次のようになります。
import 'package:equatable/equatable.dart'; class Person extends Equatable { const Person(this.name); final String name; @override List<Object> get props => [name]; } ... final taro1 = Person('Taro'); final taro2 = Person('Taro'); print(taro1 == taro2); // true
このように比較対象となるプロパティを List に入れて props というゲッターで返すだけで、
そのプロパティ同士の比較をして同一性が判定されるようになります。
とても簡単ですね。
equatable とコレクション
この equatable では内部で package:collection が使用されていて、コレクションの比較までできるようになっています。
先ほどと同じ [1, 2, 3] という List を用い、その List を持つクラスのオブジェクト同士が同一と判定されるかどうかを見てみましょう。
class MyList extends Equatable { const MyList(this.list); final List<int> list; @override List<Object> get props => [list]; } ... final list1 = MyList([1, 2, 3]); final list2 = MyList([1, 2, 3]); print(list1 == list2); // true
ちゃんと同一だと判定されました!
これができるなら、Freezed の機能のうち同一性の部分は代替方法があると言えるのではないでしょうか。
equatable の機能をもっと検証
でもコレクションがもっとネストしていたり別のオブジェクトを含んでいたりしても大丈夫なのでしょうか。
そう思いながら使うのは安心できませんので様々なケースを確認していきます。
Map
class MyMap extends Equatable { const MyMap(this.map); final Map<String, int> map; @override List<Object> get props => [map]; } ... final map1 = MyMap({'a': 1, 'b': 2, 'c': 3}); final map2 = MyMap({'a': 1, 'b': 2, 'c': 3}); final map3 = MyMap({'b': 2, 'c': 3, 'a': 1}); print(map1 == map2); // true print(map1 == map3); // true
同一と判定されました。
フィールドの順序は同一性に影響しないようです。2
これは Freezed でも同じです(コードは省略しますが確認済みです)。
Map の順序に関する補足
Map は実は抽象クラスであり、どのような種類になるのかは実装によるのですが、デフォルトコンストラクタ(factory)や
リテラルは LinkedHashMap を生成するようになっています。
HashMap には順序がなく、LinkedHashMap にはあります( 関連記事 )。
それを踏まえると、MyMap の map というプロパティは LinkedHashMap なので順番が保持されるわけですが、
だからといって「二つのオブジェクトが持つ Map の順序が異なれば同一と判定されない」と思って使っていると不具合が起こります。
ご注意ください。
List
先ほど Map のフィールドの順序を見たので、List の要素の順序も見ておきましょう。
List は index が大事なので順序が無視されることはないと思いますが、念のためです。
少し前に書いた MyList をそのまま使って確認します。
final list1 = MyList([1, 2, 3]); final list2 = MyList([3, 2, 1]); print(list1 == list2); // false
ちゃんと false になりました。
ネストしたコレクション
Map の中に Map、さらにその中に List がある構造で試してみます。
class NestedMap extends Equatable { const NestedMap(this.map); final Map<String, Map<String, List<int>>> map; @override List<Object> get props => [map]; } ... final map1 = NestedMap({ 'a': {'b': [1, 2], 'c': [3, 4]}, 'd': {'e': [5, 6], 'f': [7, 8]}, }); final map2 = NestedMap({ 'd': {'f': [7, 8], 'e': [5, 6]}, 'a': {'c': [3, 4], 'b': [1, 2]}, }); print(map1 == map2);
このように深くて複雑な構造でも同一性の判定に支障がないことを確認できました。
オブジェクトを含むオブジェクト
中のオブジェクトとそれを持つオブジェクトの両方で同一性判定の機能を持たせておけばいいはずです。
つまり、関連するクラスすべてで Equatable を使うということです。
では試してみます。
class Person extends Equatable { const Person({required this.name, required this.age}); final String name; final int age; @override List<Object> get props => [name, age]; } class Members extends Equatable { const Members(this.list); final List<Person> list; @override List<Object> get props => [list]; } ... final sakura = Person(name: 'Sakura', age: 22); final taro1 = Person(name: 'Taro', age: 20); final taro2 = Person(name: 'Taro', age: 25); final members1 = Members([sakura, taro1]); final members2 = Members([sakura, taro1]); final members3 = Members([sakura, taro2]); print(members1 == members2); // true print(members1 == members3); // false
Person クラスでは name と age の両方が一致している場合だけ同一と判定され、
Members クラスでは Person のオブジェクトの List を比較して判定されるようにしています。
それによって、sakura と taro1 の List を持つ members1 と members2 は同一と判定され、sakura と taro2
(taro1 と年齢違い) の List を持つ members3 は同一でないという期待どおりの結果となりました。
もし Person の同一性判定を name だけで行うようにすれば members3 も同一になります。
class Person extends Equatable { const Person({required this.name, required this.age}); final String name; final int age; @override List<Object> get props => [name]; // 判定対象からageを外した } ... print(members1 == members2); // true print(members1 == members3); // true
同一性については以上です。
何の苦労も不安もなく使えそうですね!
equatable パッケージには mixin も用意されています。
詳しくはドキュメントの EquatableMixin
の部分をご覧ください。
ついでに得られる利点
同一性とは関係ないのですが、
class Person { const Person(this.name, this.age); final String name; final int age; } ... const john = Person('John', 42); print(john); // Instance of 'Person'
のようにクラスを作ってそのオブジェクトを print すると、「Instance of 'Person'」と出力されて中身のプロパティの名前やそれが持つ値の情報は出力されません。
一方 Equatable を継承したクラスでは、予め用意されている toString() によって良い感じに出力されます。
先ほどのクラスに Equatable を用いると下記の出力になります。
Person(John, 42)
ちょっとしたことですが便利ですね。
もちろん Freezed もそこはうまくできていますが、この機能も equatable で代替できることを確認できたことになります。
続編もあります
immutability についても あまり間をあけずに公開したいと思います。
書きました。
Cloud Firestoreを用いてリアルタイムチャットに挑戦
モバイルアプリのクライアント側では何度も利用経験があり、タイトルの「初挑戦」は設計面のことです。
関連記事:
kabochapo.hateblo.jp
昨年末に上記教材(公式の動画やドキュメント)で学び、年明けに初めて設計から取り組みました。
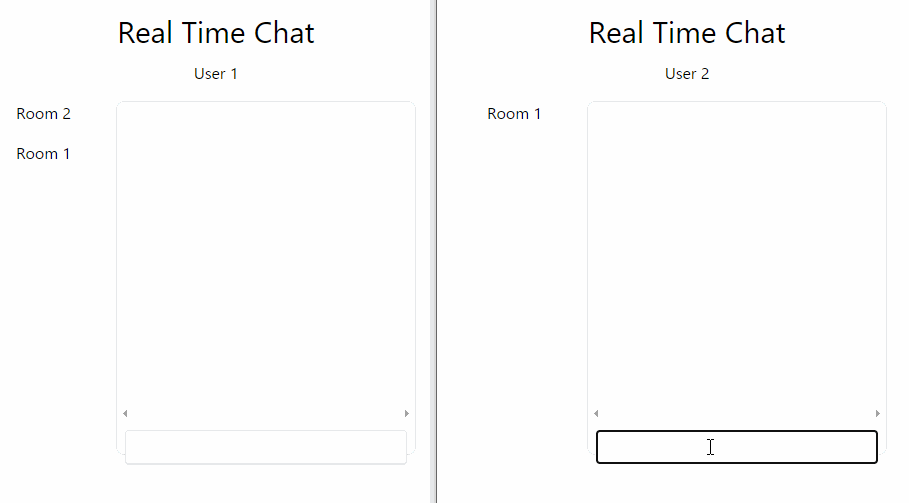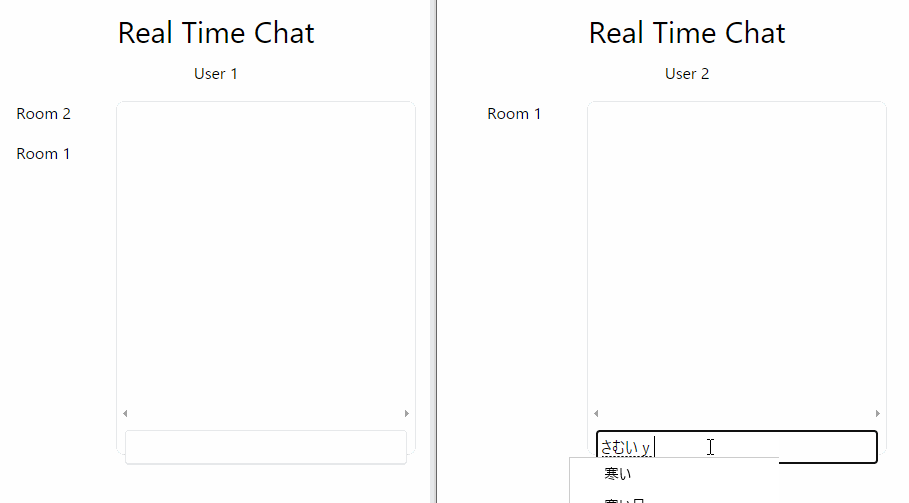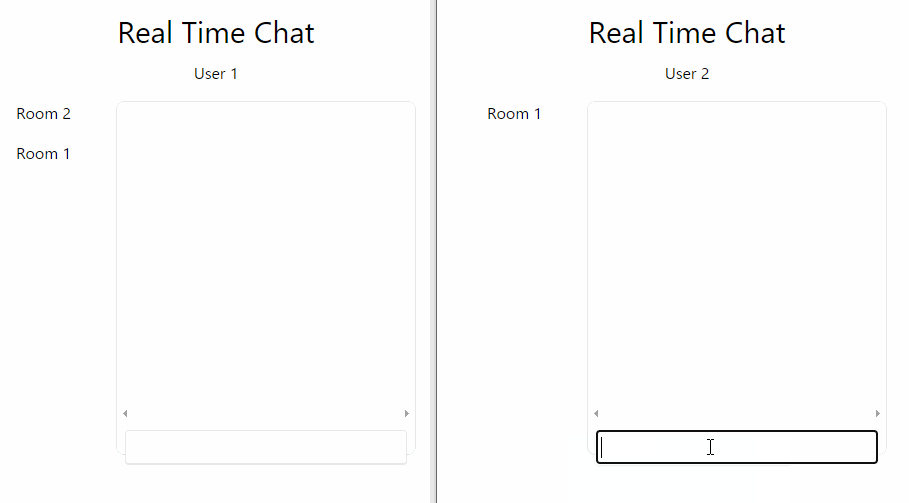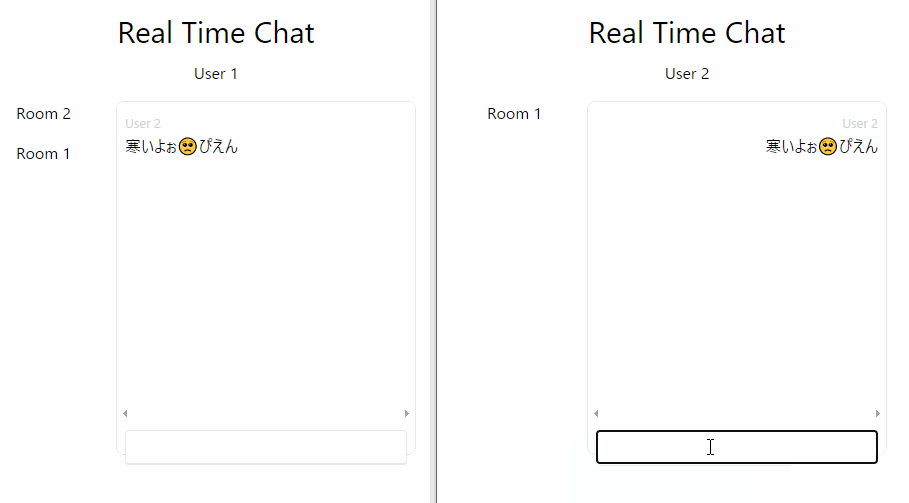
Vue.js の動画に出てきたリアルチャットアプリ(Firebase Realtime Database 利用)を拡張しつつ Firestore に置き換えたものです。
元はチャットルームの機能もユーザ制限もなく、送信後の絵文字の自動付加もありませんでした。
そのあたりが自分で拡張した部分です。
工夫したこと、苦労したこと
リアルタイム更新
過去メッセージの編集や削除の機能は無し。
リアルタイムな取得は新メッセージだけなので、直近 N 件を get() してから、それより後をクエリカーソル指定して onSnapshot() で listen することにしました。
Read の抑制
メッセージごとの document を大量取得すると費用が多くなるのでパジネーションを入れました。
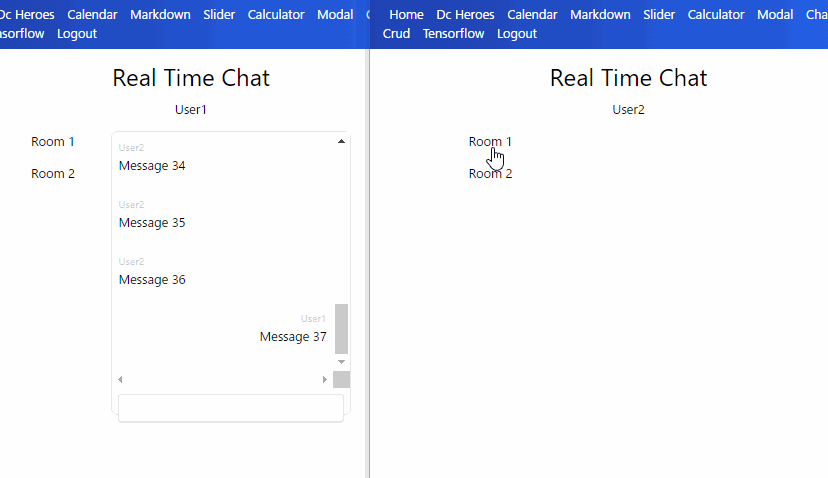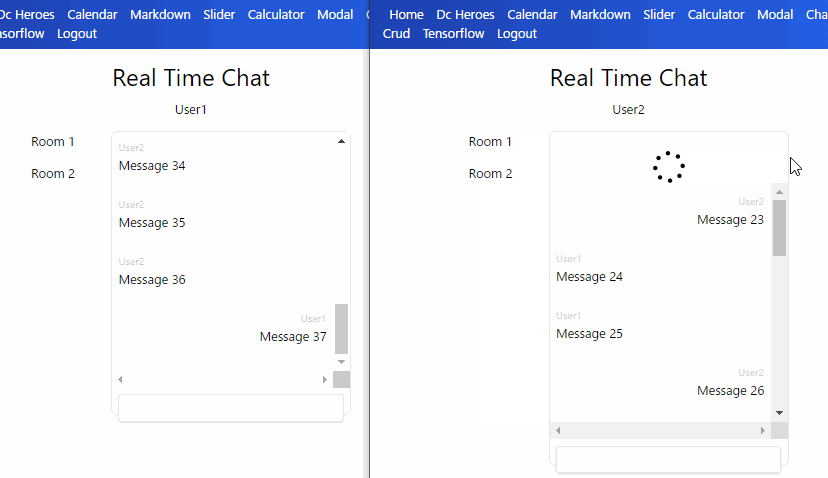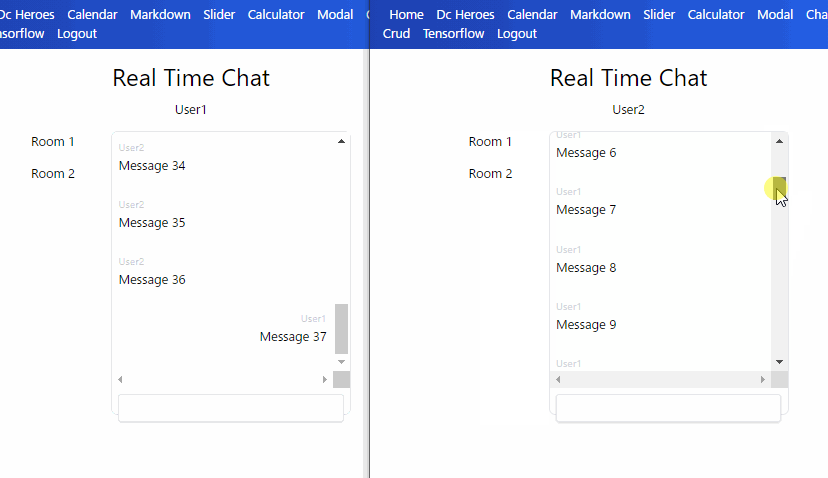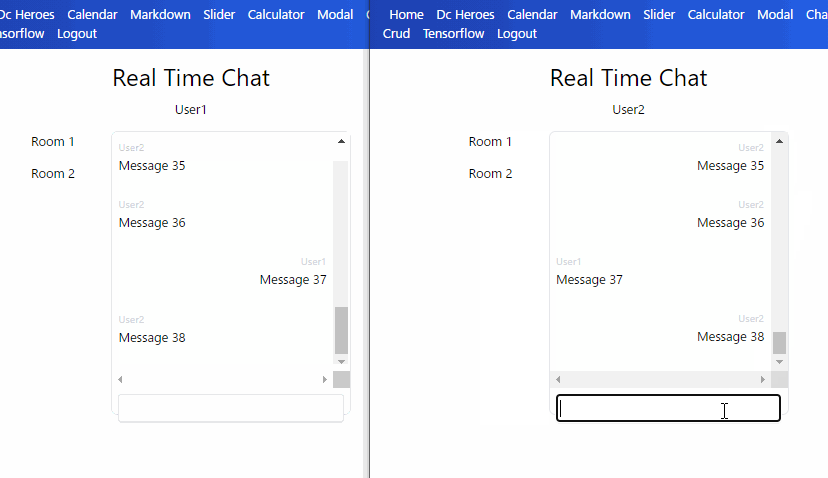
もし過去メッセージもリアルタイム更新するとしたらパジネーションとの組み合わせが大変そうです。
ページごとに listen し、ページ内のメッセージがなくなったら listener を破棄する必要があるかと思います。
クエリカーソル
startAfter() が機能しなくて悩みました。
エラーが出ず、startAfter() なしでクエリしたときと同じ結果が返ってきていました。
原因は QueryDocumentSnapshot ではなく DocumentReference を渡してしまっていたという凡ミスです。
間違っているなら警告してほしいです…。
Firestore のメソッドで返ってきたものが何を表しているのか理解せずに使っていたのも良くなかったです。
↓
後で調べて記事にしたので、理解があやふやな方は見てみてください。
qiita.com
チャットルームを利用できるユーザの制限
ルームの document の下に subcollection を作り、その中の document に members という配列フィールドを持たせて、ルームの参加メンバーの ユーザ ID を入れるようにしました。
これは次の理由によります。
- クライアントで取得するメッセージデータに参加者データを含めないため
- 参加者データはアクセスを制限するためのものであり、ルームの document には不要です
- 参加者データへのアクセスをセキュリティルールで制限しやすくするため
- (結局やりにくかったです…)
rooms
├ xxxxxx
│ ├ messages
│ │ ├ xxxxxx
│ │ └ xxxxxx
│ └ private
│ └ allowed - members [xxxxxxxx, xxxxxxxx] ← これ
└ xxxxxx
├ messages
│ ├ xxxxxx
│ └ xxxxxx
└ private
└ allowed - members [xxxxxxxx, xxxxxxxx] ←
下記のように subcollection の document を参加ユーザ単位にする(document の ID をユーザ ID にする)ことも考えましたが、document の読み取りが増えるのでやめました。
また、document 内に持たせるデータが特にないので配列のほうがいいなと思いました。
rooms
├ xxxxxx
│ ├ messages
│ │ ├ xxxxxx
│ │ └ xxxxxx
│ └ private
│ ├ xxxxxxxx ← これ
│ └ xxxxxxxx ←
└ xxxxxx
├ messages
│ ├ xxxxxx
│ └ xxxxxx
└ private
├ xxxxxxxx ←
└ xxxxxxxx ←
配列にしたことでセキュリティルールに苦労した(後述)ので、楽なのは後者のほうかもしれません。
Collection group
ユーザ ID は複数の subcollection からまとめて取得するので、colletion group を使いました。
動画等の説明によると、collection group のインデックス設定ができていないままクエリを実行するとブラウザのコンソールに設定用の URL が出てくるとのことでしたが、なぜか出なかったので Firebase コンソール上で自分で設定しました。
クライアント側
subcollection 内のユーザ ID の有無によって親 document を取得できると思っていたのですが、subcollection のクエリで取得できるのは subcollection の document だけだとわかりました。
それを取得してから subcollectionDoc.ref.parent.parent.get() と遡って取得しないといけません。
子と親の両方の document を取得することになるので、費用に関わる Read のカウントが増えます。
セキュリティルール
collection group 用のセキュリティルールが必要なのを忘れていて、しばらく取得できずに悩みました。
設定画面にある playground で get のシミュレーションをしても正常でした。
問題があったのは collection group の場合だけだったのです。
playground では collection group のクエリのシミュレーションはできないようで、不便に思いました。
直した最終的なルールは下記です。
match /{path=**}/private/{document} {
allow read: if request.auth.uid in resource.data.members;
}
これの前のルールは次のようにしていました。
match /{path=**}/private/{document} {
allow read: if request.auth.uid
in get(/databases/$(database)/documents/$(path)/private/$(document)).data.members;
}
わざわざ get() する(document を一回読み取ったことになる)のは無駄があります。
ルールの get() や exists() はヒットしなくても課金対象になるようです。
無駄ではあっても間違ってはいないと思っていましたが、実際には無駄+間違いでした。
先ほどのクエリで「Uncaught (in promise) FirebaseError: Missing or insufficient permissions.」というエラーが出ました。
どうしても理由がわからないので Stack Overflow で質問をして原因が判明しました。
記事が長くならないよう省略しますので、SO の回答で確認してください。
もう一つ悩んだのが、private 内には allowed だけが必ず存在するのに
match /{path=**}/private/allowed {
のようにワイルドカードを使わずに直に指定するとデータを取得できなくなったことです。
これも Stack Overflow で質問したところ、公式動画シリーズの Doug さんから回答をもらえました。
試していませんが、collection group のルールで特定の document ID を使えないなら、その ID は自動附番で良い気がします。
セキュリティルールの質
セキュリティルールは正しく設定すれば守ってくれて心強いもののはずです。
しかし、ちょっとしたミスでアプリが機能しなくなるのを経験して怖くなりました。
安全のためのルールが効いていなくてザルになることもありそうです。
上記のようなことを防ぐためには、ルールのテストが必須に思えました。
まだそう思えただけであり、実際のテストは書いていません。
下記公式ブログ記事にテストやレビューのことが書かれているので参考にしたいと思います。
subcollection に分けるもの
上のブログ記事に書かれていますが、少なくとも個人情報は分ける必要がありそうです。
あとは、分けないとクライアントで取得する document データに含まれてしまって無駄に多くのデータを取得することになってしまうケースかなと思いました。
先ほどのアクセス可能なユーザの ID は、漏れてはならない個人情報でもないかもしれません。
分けたことで取得に手間がかかり、セキュリティルールでも混乱したので、分けずにルームの document に含めたほうが良かった気がしています。
Cloud Functions
Cloud Functions も使えるようになっておかなければ、と思って使ってみました。
冒頭の GIF アニメに見えるように、新たなメッセージが送信されたときに末尾に「🥺ぴえん」を自動的に付ける Function を作ってみました。
シンプルな機能なので何も難しいところはなく、あっさりとできました。
なお、Cloud Functions の料金は Container storage のみは無料枠がないようです。
使い始める前に従量課金のプランである Blaze プランへのアップグレードと請求先の設定を求められましたので、少しでも使うと支払いが生じるのだろうと思います。
さいごに
いろいろとハマりどころが多くて大変でした。
Flutter の開発者の多くが Firestore を使っていて、簡単だという話ばかり聞こえてきていました。
短期間にアプリを量産してリリースしている人も目にします。
実際に学んで使ってみるとそれほど簡単ではなく、DB 構造などの工夫が必要で、注意点も多かったです。
それなのになぜ皆簡単に感じながら使えているのか…。
あまりドキュメントも読まずに使い始めて何となく使っている人が多いのかも、と思いました。
もしセキュリティルールを「安全でないルールがあります」の警告メールが来ない程度にいじっただけのアプリを公開すると、悪意のある人が他人のデータを閲覧できたりしてしまうのでしょうか…。
そんなアプリが世の中に溢れないことを願います。
Firebaseの学習教材(Cloud Firestoreなど)
学習開始の経緯
フリーランスの仕事で大きなアプリの設計をすることになりました。
バックエンドには慣れた技術を使って良いと言われているので、もし何も気にしなくて良ければデータベースには RDB を使いたいところです。
しかし同社からいただくお仕事は基本的に Firebase 利用です。
RDB なら API サーバなど一体的な開発になり、保守できる人の確保が難しいかもしれません。
費用面では RDB は高額になる可能性があります。
そんなわけで Firestore に決めました。
目標
問題は、私自身は Firestore のモバイルアプリのクライアント側しか経験がないことです。
下記のような不安ばかりなので、それがなくなって設計できる状態になるのが目標です。
- 開発開始までに Firestore/NoSQL の特性を理解し、それに適した構造の設計ができるのか
- 失敗すると…
- Read/Write が多くなりすぎて費用が多額になる
- 気づいたときにはもう直しにくい、等
- 安全な作りにできるか(難しそうなセキュリティルールを適切に扱えるのか)
- Cloud Functions など周辺のサービスまで把握してうまく連携させられるか
個人アプリ開発での活用
Flutter のアプリ開発者には Firestore の利用者が非常に多いです。
一方私は、他の DB を使っていて困ることがなく、費用も海外サーバで €3 程度で済ませているので、積極的に導入する動機がありませんでした。
それであっても、使えるようになれば自分でサーバを用意・保守していく手間が省けます。
これはとても大事で、生活のために多数のアプリを出していっても保守の負担を増やさずに済みます。
また、ユーザが少ない間は €3 どころか無料で済ませることができます。
RDB と NoSQL の両方を知れば、用途に合った使い分けができるようにもなります。
そういった使い方を念頭に置き、まずはシンプルなアプリに活用できるようになることを目指します。
学習内容
昨年末のクリスマス頃までの 4 ~ 5 日を Firestore +α の集中学習期間としました(動画とドキュメント)。
その後、年明けには実際に手を少し動かす形の実践も行いました。
Firestore の公式動画シリーズ
15 分前後の動画が 12 本だけ(単純計算でたったの 3 時間)なのでここから始めました。
ところが予想外に時間がかかりました。
新たなことを学ぶので、漏れなくしっかりと理解しようとすると流し見するだけでは不十分で、途中で止めつつ調べたり前の動画を見直したりしました。
動画は可愛いキャラクターや Todd さんの楽しいノリが織り交ざっていて苦痛でないのが幸いでした。
その後に読んだドキュメントだけでは理解しにくそうな大事な情報が詰まっているので必見です。
要点をしっかりと含めながら広範囲を平易に解説されていて素晴らしいです。
二種類の Cloud Functions
最後の 2 本は Cloud Functions for Firebase を組み合わせる話でした。
その一つ目で Functions には二種類あることを知りました。
こちらは Cloud Functions for Firebase であり、もう一つは Google Cloud Functions です。
使う言語は Go がいいと思っていましたが、後者でないと使えないとのことでした。
(この記事 によれば使えないこともないようです。)
TypeScript は JavaScript 経験者向けの下記ガイドを読むだけで基本はわかったので、まあ OK です。
この時点の理解度
頭に定着させるためにこれを二周し、いわゆる「完全に理解した」状態になりました。
Functions の公式動画シリーズ
Cloud Functions のほうのシリーズで、8 分前後の動画 9 本だけです。
前の動画で既に少し理解していたせいか、難しく感じることなくすぐに見終えました。
DB のほうは SQL 脳からの大転換が必要なので二周しましたが、こちらは一回で十分だと思いました。
この時点の理解度
特に変わらず「完全に理解した」ままです。
公式ドキュメント
動画シリーズも必見ですが、さらに重要なのはやはり公式のドキュメントですね。
動画はかなり広く対応しているのですが、それでも漏れがないわけではありません。
例えば Solutions のところの分散系の話やデータのエクスポート/インポートは重要ですが動画にありません。
また、コード例はドキュメントのほうが見やすいです。
料金例 もわかりやすく示されていました。
100 万件のインストールで DAU 10 万 のチャットアプリ(グループチャットも可)だと読み書きが月 2.7 万円くらいで、ストレージとネットワークは動画内でも言われていたとおり安くて 3 千円くらい。
なお、日本語版 もありますが、英語版にある情報がなかったり、 PC で見ていると遷移先に左カラムがなくて行き来しにくかったりしました(報告しましたが直っていません)。
英語版のほうがおすすめです。
この時点の理解度
「完全に理解した」ではなくなりました。
次の段階として「何もわからない」まで下がるとよく言われますが、そこまでではないにせよ情報量が増えて「所々わからない」まで下がりました。
自分で設計するとしたら相当見直さなければできそうにないと思える段階です。
Google I/O 2019 の Firestore に関するトークの動画
最初のシリーズと同じ方によるトークで、40 分間です。
ドキュメントを一週間前に読み終えて少し自信喪失していて、年明けに見ました。
飲食店情報のアプリを例にしていて、15 分頃までは既に見た動画とほとんど同じで見る意味がなかったかと思いましたが、その先は使う際の様々な制約ごとに対策を解説する構成になっていて見る価値がありました。
小難しいドキュメントや話が散らばっている動画シリーズと違い、40 分間にまとまっていて復習に最適ですし、再びわかった気になれます。
ただし全体をカバーしているわけではなくて設計面のみです。
特に参考になったのは、DB 構造の一つの方針として画面単位の Collection にすること(アプリによります)や、非正規化を理解しにくい RDB 寄りな人へのアドバイスでした。
前者は、画面単位と無関係だけれど一つの Collection にするもの(ユーザデータなど)もあって迷うこともありそうですが、大きく間違った設計にしないための指針にはなりそうだなと思いました。
この時点の理解度
「所々わからない」ままですが、少し不安が軽減されました。
初挑戦(リアルタイムチャットアプリ)
クリスマスの後くらいから Vue.js の集中学習に移っていて、大晦日まで取り組みました。
10個のアプリを作る動画で、その一つが Firebase Realtime Database を使ったチャットでした。
それを拡張しつつ Firestore に置き換えてみました。
頭で理解しても実践しなければ実用レベルになりませんし、やってみるほうが圧倒的に速く身につきますよね。
詳細は別記事にしました。
Cloud Functions を使った送信後の自動編集と、Firebase エミュレータの利用までやっておきました。
セキュリティルールの情報
セキュリティルールはちょっとしたミスでアプリが機能しなくなることがありました。
誤ったルールにしても機能はするままで無防備になってしまうこともあり得ます。😱
より良く知るための資料として、Firebase のブログの記事が非常に良かったです。
- The Firebase Blog: 7 tips on Firebase security rules and the Admin SDK
- 様々な Tips
- The Firebase Blog: How to code review security rules
- ルールのレビューやテストの話
一つ目の「Tip #3」にある Authentication の custom claims は動画等に出てこなくて知りませんでした。
単に理解不足かもしれませんが、設定した role の設定・削除をコードで行う必要がありそうなのと、設定済みの role を一覧で確認する方法がなさそうなのが不便に思えました。
また、ID トークンのキャッシュのせいで role の変更が有効になるまで最長 1 時間かかるというのも困ることがありそうです。
この時点の理解度
作る間にドキュメントを見直したり Stack Overflow で情報を探したりしました(かなり)。
また、疑問点を曖昧なままにしておかないように自分で質問したりもしました。
そうしているうちに感覚がつかめてきた気がします。
もう少し大きめのアプリくらいなら設計できそうと思える段階です。
しかし最終形態の「チョットデキル」は遥か先です…。
それでも学習前と比較すると大きく進展しました。
他に学習に使ったもの
まとめ
動画 x 3(うち一つは二周)、ドキュメント x 1、実践 x 1(多くの検索等による調査を含む)。
一週間程度です。
私は集中力に難がありましたが、集中できる人はもっと短期間かもしれません。
また、RDB の経験がない人ならもっとすんなりと受け入れられる可能性もありますね。
これだけで概ね理解してちょっとしたアプリに使えるようになりました。
どこかの長期休暇の一つでもこれに充てるだけである程度実るわけです。
これからやってみようと思っている方は参考にしてみてください。
今後どの程度活用するか
NoSQL でやりにくいことや、できるけれど向かないことなどが少し見えました。
少し上に貼った Qiita の記事には
Cloud Firestoreだけでサービスを作ることは不可能ではない
でもしんどい。
と書かれていました。
また、下記 Q&A を見て RDS の良さを再確認しました。
作るものに適していて苦しいところがなければ Firestore を使い、そうでなければ RDB を使うと思います。
Firestore と RDB の併用も選択肢に含めておきます。
もし Amazon Aurora の機能性で Firestore 並みに安いものがあれば迷わず選ぶのですが…。
Firestore 以外の Firebase のサービスは、Authentication など自分で実装しないほうがいいものは積極的に活用していきます。
例外(Exception)って扱いにくくない?
例外の長い歴史の中で既に語りつくされている気がしますが、既存の情報をあまり見ていないのでわかりません。
記事のカテゴリとして Dart を含めていますが、例外を持つ様々な言語で共通するところがあると思います。
経験など
昨年まで業務で PHP、JavaScript などを使っていました。 PHP の例外は PHP 5 から存在していて入社はそれより後でしたが、まだ無かった頃のレガシーなコードも扱うことがあり、ライブラリを利用するときか自作するときに使うくらいでした。
一方、業務外で使っていたのは Go で、そちらには例外がありません。
panic という似たものはあっても非なるもの(例外と同様の使い方をするべきではないもの)です。
Go で例外の代わりにエラーを伝えるには、関数が多値を返せるという言語仕様を活用します。
第二戻り値などで error 型かそのインタフェースを実装した型の値を返し、受け取った側は nil かどうかでエラーの有無を判断したり型で種類を判断したりするだけなので単純明快です。
そんなわけで、戻り値を使う方式により慣れていて、例外は不慣れでした/(今も)です。
例外への抵抗感
- Java でのつまづき
- 「非検査」例外は対処しなくて良さそうな名前なのに対処が必要なの?(戸惑い)
- 非検査例外 とは、RuntimeException やそのサブクラス??
- サブクラスかどうかはどうやって知るの?
- 大昔なので現在ほどの IDE の支援はなかった
- 今考えれば、型の確認をすれば良いのかも
- サブクラスかどうかはどうやって知るの?
- どこで例外が起こるのかわかりにくい
- サードパーティのライブラリで例外が発生し得るのにドキュメントに書かれていなくて苦労した
- 例外を握りつぶす人がいる
- 頻発して困るからといってチームメンバーが理解しないまま
catchして揉み消していた(涙)
- 頻発して困るからといってチームメンバーが理解しないまま
握りつぶしについては、社内のレベルの低さを表していると思って当時悲しかったのですが、ネットで調べてみる と割とよくあることだとわかりました。1
実際のところどうなのでしょう? 周りにそんな人はいますか?
いるとすれば、例外がわかりにくい / 扱いにくい / 握りつぶしやすいことを物語っているように思えます。
例外と向き合うようになって感じたこと
Flutter でアプリ開発をするようになって Dart を日々使うことになり、例外にも向き合わねばならなくなりました。 モバイルアプリ側の例外発生からユーザ向けエラー表示までの流れをどうしたものかと悩みました。
もう慣れはしましたが、例外を例外のままうまく扱う方法は見つからず、次のようなことを感じました。
- 捕捉しないとプログラムがそこで停止してしまうのが怖い
- Flutter 製のアプリはそれでも落ちないが、例外が起こったメソッドから適切な戻り値が返らない
- Error と違ってランタイムで発生するものなので開発中に起こらずにバグが潜在し得る
- 捕捉したとしても、そこからエラーの種類を UI 等に伝える方法の工夫が必要
- 成否を bool 型で表すメソッドの場合、例えば「通信の異常が原因」を呼び出し元にどう伝える?
- 既に捕捉&対処が済んでいるのかどうかわかりにくい
- 上記を解決するために UI の箇所(などエラー情報を必要とする箇所)で捕捉するのも困る
- 多段にメソッドを呼び出した先で発生したとき、途中のメソッドも何らかの対処が必要な場合がある
- 途中で捕捉して rethrow すれば良いが、そのせいで多重にロギングしているコードがあった
- そもそも捕捉せずにレイヤーを突き抜けさせるのは良くないのでは
- Model の層の例外を丸投げして UI 層がその知識を持たなければならなくなるのは避けたい
- 例外に持たせたメッセージをそのままユーザ向けに表示してしまっているアプリがあった
- 例外の種類が様々にありすぎて、発生と捕捉の箇所が離れるほど対処すべき種類が多くなる
- 例えば API アクセス時に通信・サーバ・パラメータ・データ等に起因する各例外があるとすると、最寄りの呼び出し箇所ではその限られた例外だけに対処すれば済むが、離れた箇所では途中のメソッドで起こり得る他の例外にも対処する必要がある
- 多段にメソッドを呼び出した先で発生したとき、途中のメソッドも何らかの対処が必要な場合がある
みんな悩まないの?
Flutter ではいつも「状態管理」がくどいほど話題になります。 エラーハンドリングも似た面があると思いますが、なぜか悩みとしてほとんど聞きません。
あまり聞かないだけで、うまくハンドリングできていない(のに気づいていない)人が実は多いのでしょうか。
- 作った本人が気づかないまま起こってしまっている可能性
- 先述のような、多重にロギングしてしまうケース、例外のメッセージが時々そのまま表示されてしまうケース 2 などもこれ
- Flutter では例外時に落ちないで動き続けることが悩みを表面化しにくくさせている可能性
- フロントエンドでは DB 等の例外をバックエンドほど不安視しない可能性
- ローカル DB 関連の失敗はストレージの空き不足など特殊な状況でしか起こらないという考え
- Firestore などに接続失敗してもローカルのキャッシュで動くからいいという考え
- 大勢のデータが消える、他人のデータが見える、といった重大な事態に至らないという考え
その後 Reddit で同じような悩みを持っている人がいましたが、程々の盛り上がりで終わりました。
代替方法
みんなが悩まなくても私は悩みます。 また、悩む人が少なければ関連記事も少なくて、自分で考えなければなりませんでした。
そんな中でいただけた情報
Twitter でつぶやいてみたところ、有力な方法を一ついただけました。
Dart の package:async が持つ Result というクラスを使う方法でした。
これは何らかの処理の結果またはエラーをラップするもので、そのラップしたものを戻り値として返し、受け取った側でエラーの有無による条件分岐で通常の処理とエラーハンドリングを行えます。
良い点
Result型が返されることでハンドリングが必要だとわかる- 非同期処理に使う
Future型やリアクティブなStream型も capture してResult型にできる
気になった点
Future等を capture した場合、Futureの処理内で起きた例外がそのまま伝えられる- 結果かエラーをいちいち
Resultで包まないといけない
包むのは最初は煩わしく感じられましたが、例外を避けてあえて戻り値で結果/エラーを受け渡ししようとするわけですから、どうしてもそうなります。 むしろ単純で好ましく思えるようになりました。3
なお、この Result に似た手法が他の言語でも使われているようです。
下記の記事に目を通した感じでは Scala と Rust はそれに近いものに思えました。
自分の方法
Result の情報をいただいたときに既に考えがあり、それから実装して先月パッケージ化しました。
しかし最近になって重大なバグに気づき、修正のために大幅に作り直したところ、結局 Result に似たもの(渡し方は逆方向)になってしまいました。
最初の仕様
- 例外は発生の最寄り箇所で捕捉する
- 起こった例外を独自のエラー型の値(enum など)に置き換えて通知する
- 別の層の例外を UI が意識する必要がなくなり、UI の関心に沿った独自エラーを UI 層で受け取れる
- そのようなエラーが起こり得る処理を
scope()というメソッドに渡して実行 - エラーの通知があると listener が呼ばれる
- そこで直近のエラーの値が保管される
- 同時にロギングも可能
- スコープが終わったとき、指定した条件に該当していればエラーハンドラが呼ばれる
- 条件は処理結果かエラー種類を使って設定
-
!resultとかerror == ErrorTypes.connectとか
-
- エラーハンドラはあらかじめセットしておくこともスコープごとにセットすることも可能
- 条件は処理結果かエラー種類を使って設定
重大バグ発覚
- スコープとその中で実行される処理の間で紐づけをしていなかった
- スコープの開始順にエラーが通知されてくると想定してしまっていた
- そのため、所要時間が異なる複数スコープが非同期に実行されると誤作動する
- 例えば、通知~スコープ終了の間に時間がかかって終わる順序が前後するとダメ
修正(大改修)
- スコープと処理の紐づけのために、スコープ内で作ったオブジェクトを引数で処理に渡す方式に変更
- そのオブジェクトが持つ通知メソッドを使うことで、どのスコープの処理のエラーなのかわかる
Resultが戻り値でエラーを返すのに対して逆方向に引数でオブジェクトを渡している
- その代わり、メソッドがエラー通知用オブジェクトを引数に取るのを見てハンドリングの必要性がわかる
- これも
Resultが戻り値でエラーハンドリングの必要性を判断できるのに似ている
- これも
こうなると Result で足りた説が出てきます。
そうかもしれません。
一応利点を挙げておきます。
利点
- あらかじめエラーハンドラとロガーを設定しておけるのでエラー発生ごとに書かなくて済む
- エラーハンドラを見ればエラー種類ごとの対処方法(エラー表示等)がどうなっているかわかる
- エラー確認箇所で必ず
scope()を使うので、ソースコード全体から探し出しやすくなる - 例外を早く捕捉して独自のエラー型に置き換えるよう README に明記している
これらが魅力に思えないなら Result で足りるでしょうし、Dart チーム製なので安心できるでしょう。
というわけで自作パッケージの名前は伏せますが、万一人気が出るようなことがあれば別記事にして紹介します。
【Flutter】LicensePageのテキストのスタイリング
アプリでは、使っているフレームワーク、ライブラリ、パッケージ等のライセンスを表示する必要がありますね。
Flutter では LicensePage という widget を使うだけで表示することができます。
しかも Flutter 1.20 で 刷新 されて見やすくなりました。
ところが、そこに自分で追加したテキストをきれいに見せるのは簡単ではありませんでした。 この記事は下のような表示にするのに少し苦労した話です。 わかってしまえば簡単です。

適当に載せた場合
ライセンスページを見ていると、こんな表示になっているパッケージもあります。

これは酷いですね…。
でもライセンスページに自動追加されたものは、パッケージの作者がライセンステキストをどう書いているかによります。 使用者であるアプリ開発者がどうこう言う部分ではありません。
しかし、アイコン等の素材は別です。 そのライセンスは自分で追加しなければなりません。
まず何も考えずに追加してみた結果がこちらです。

インデントと箇条書きで見やすくしたつもりが、意図通りの表現になりませんでした。
素敵な素材の提供者に敬意と感謝の気持ちを表して、もっと見やすく表示したいのですが…。
きれいに表示される例
テキストによっては、一部がインデントされていたり太字でセンタリングされていたりします。 そのようにスタイリングする機能が一応備わっているのだろうと考えました。


スタイリングの方法を調べた過程
ではどうやってやるのでしょうか? 方法を Web 検索してみても情報が全然出てきません。
そこで仕方なく ソースコード を見ました。
どうでしょう。ご自分で読み解けますか?
お急ぎの方(TL;DR)
この記事は、ソースコードを見て方法を調べた過程を書いた「読み物」(兼、著者のメモ)です。 「なんで簡単にわかるようになっていないの?」という不満も少し込めています。
手っ取り早く方法を知りたい方は末尾のまとめをご覧ください。
ソースコードを眺める
LicenseParagraph というクラスがあり、そこに indent や centeredIndent というプロパティが存在しています。
コメントを消して短くすると下記のようになります。
class LicenseParagraph { const LicenseParagraph(this.text, this.indent); final String text; final int indent; static const int centeredIndent = -1; }
indent はインデントに関する値、centeredIndent はセンタリングさせる場合に使う定数、おそらく。
これを使えばできそうに思えましたが、LicenseEntryWithLineBreaks というクラスの中で使われているものでした。
class LicenseEntryWithLineBreaks extends LicenseEntry { ... @override Iterable<LicenseParagraph> get paragraphs sync* { ... LicenseParagraph getParagraph() { ... final LicenseParagraph result = LicenseParagraph(lines.join(' '), currentParagraphIndentation!); ... return result; } ... } }
どうやらこの LicenseEntryWithLineBreaks がスタイルの詳細を実装している部分です。
それを使わずに自分で LicenseParagraph を利用するクラスを作ると、他の細かな実装も自分でしないといけなくなります。
LicenseEntryWithLineBreaks の 肝となる部分 は画像のとおり面倒くさい感じです。
一文字ずつ確認しては計算などしていくループになっています。

case '\t': のところに currentLineIndent += 8; という加算処理があります。
行頭に \t(タブ文字)があるとインデントが 8 文字分になるように読めます。
一方、半角スペース 1 つはそのまま 1 文字分とされています(currentLineIndent += 1)。
でも 1 文字分のインデントって変ですね。よくあるのは 2 文字・4 文字・8 文字あたり。
とりあえず試しにスペース 2 つを行頭に加えてみたところ、インデントされませんでした。
ソースコードを読み進めると、その理由となる 箇所 がありました。
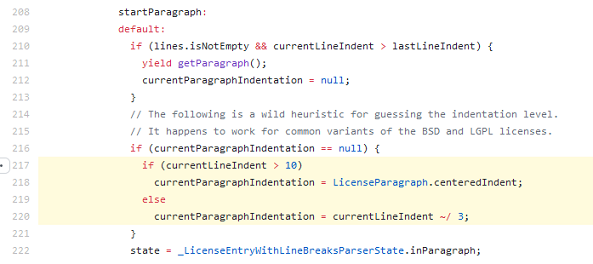
ここでインデントのレベルが計算されています。
currentLineIndentを 3 で割った数(整数)がインデントのレベル- ただし割る前の数が 10 を超えていればセンタリング
currentLineIndent += 8; の 8 はそのまま表示する文字数ではなく、インデントを計算する基になる値なんですね。
10 を超えていないので 3 で割って深さ 3 のインデントとして扱われることになります。
これでだいたい理解できました。
検証
あと少し疑問が…。
- タブ文字が 8 なら、タブ文字 (8) + スペース (3) で計 11 になってセンタリングされるの?
- 改行するには改行を 2 つ入れれば良いみたいだけれど、3 つ以上入れるとどうなるの?
などなど。
で、試しました。

まとめ
- インデント
- 行頭のスペース 3 個ごとに 1 インデント
- 行頭のタブ文字 1 個で 2 インデント(スペース 8 個扱い)
- センタリング & 太字
- 行頭のスペース 11 個以上
- タブ文字 2 個でも OK(スペース 16 個扱い)
- タブ文字 1 個 + スペース 3 個でも OK(スペース 11 個扱い)
- スペース 11 個以上ならいくつ増やしても変わりなし
- 前の行との間が少し広くなる
- 行頭のスペース 11 個以上
- 改行
- 改行文字連続 2 個以上で 1 改行(3 個以上でも 1 改行のみ)
- 行途中のスペース / タブ文字
- 1 個ごとに 1 余白
- 行途中の改行文字
- 1 個で 1 余白(2 個以上は改行)
- テキスト先頭の改行文字 1 個
- 効果なし
ちょっと Markdown に近い感じがありますが、似たところがあるだけで扱いづらいですね。 ソースコードも頭の良い人が作ったんだろうなぁ…という(個人的に保守しにくく感じる難解な)書き方でした。
以上。
Goのスライスの性質を再確認
下記のようなコードが期待通りの結果にならないというのを先日 Twitter で見ました。 そのツイートのままではありませんが似たコードです。
問題のコード
func main() { s := []string{"0", "1", "2", "3", "4"} fmt.Println(s) // [0 1 2 3 4] s2 := append(s[:2], s[3:]...) // 二番目の要素を削除 fmt.Println(s2) // [0 1 3 4] fmt.Println(s) // 元のスライス [0 1 3 4 4] }
先頭を「0番目」と呼ぶとすると、s2 の2番目の要素が削除されるのを期待するわけですが、削除されるだけでなく元のスライスに影響してしまっています。
SliceTricks に書かれている方法
スライスの一部の要素を削除する方法は、公式 Wiki の SlickTricks では次のようになっています。
a = append(a[:i], a[i+1:]...) // or a = a[:i+copy(a[i:], a[i+1:])]
先ほどのコードではこの一つ目のほうと同じ方法が使われています(それなのにダメ)。 二つ目の方法ではどうでしょうか。
s2 := s[:2+copy(s[2:], s[3:])] fmt.Println(s2) // [0 1 3 4] fmt.Println(s) // 元のスライス [0 1 3 4 4]
同じように元のスライスに影響してしまいました。
上記の方法にはメモリリークの恐れがあり、次のようにすれば防げるとも書かれています。
copy(a[i:], a[i+1:]) a[len(a)-1] = nil // or the zero value of T a = a[:len(a)-1]
でも元のスライスを削除結果で上書きするときにしか使えないため、今回の問題の解決にはなりません。 *1
対策
結論を言ってしまえば、記述を二文字増やすだけです。
//s2 := append(s[:2], s[3:]...) // ↓ 変更 s2 := append(s[:2:2], s[3:]...)
少し前に書いた記事と共通したスライスの性質に関することなので、この方法に気づけました。
でも怖いですよね。 そういうものだとわかっていても、自分が書くときに毎回確実に気づける自信はありません。 気づけなければ潜在的な不具合となってしまいます。
そこで、スライスを扱うときには容量までを意識する ことを脳に刻み込むためにこの記事を書きました。
原因を見る前にスライスの性質を確認
情報を出力する関数は前回と同じものを使います。
func showSliceInfo(s []string) { fmt.Printf("len:%d cap:%d %p %v\n", len(s), cap(s), s, s) }
値の変化だけでなく長さ・容量・アドレスも見ます。
s := []string{"0", "1", "2", "3", "4"} showSliceInfo(s) // len:5 cap:5 0xc00005c050 [0 1 2 3 4] // 2番目の要素までをスライス // 容量は5のまま、かつ同じ配列を参照したまま s2 := s[:2] showSliceInfo(s2) // len:2 cap:5 0xc00005c050 [0 1] // 長さを5に戻すと元のスライスと同じになる // 参照先配列も同じまま s3 := s2[:5] showSliceInfo(s3) // len:5 cap:5 0xc00005c050 [0 1 2 3 4] // 3番目以降の要素だけをスライス // もともと4番目までしかないので長さも容量も2になる // 参照先は元の配列の3番目~ s4 := s[3:] showSliceInfo(s4) // len:2 cap:2 0xc00005c080 [3 4] // s2にs4をappend // 長さ2+2で4になるが容量はs2と同じ5のまま s5 := append(s2, s4...) showSliceInfo(s5) // len:4 cap:5 0xc00005c050 [0 1 3 4] // s2はsと同じ配列を参照しているのでs2の変更がsにも反映されている // sは長さも容量も5であり4番目の要素は元のまま showSliceInfo(s) // len:5 cap:5 0xc00005c050 [0 1 3 4 4] // appendした結果を入れたs5も長さを5にすれば4番目の要素が出てくる s6 := s5[:5] showSliceInfo(s6) // len:5 cap:5 0xc00005c050 [0 1 3 4 4] // 元のスライスを容量も指定してスライス // 参照先の配列は同じまま s7 := s[:2:2] showSliceInfo(s7) // len:2 cap:2 0xc00005c050 [0 1] // 容量を2にしたものを5に戻すことはできないので // 3~4番目の要素が出てきてしまうことはない //s8 := s7[:2:5] // 長さと容量が2のスライスに一つappend // 長さ・容量・アドレスが変わる(ここがポイント) s9 := append(s7, "5") showSliceInfo(s9) // len:3 cap:4 0xc000016080 [0 1 5]
原因の確認
同じ感じで見てみます。
対策前
s := []string{"0", "1", "2", "3", "4"} showSliceInfo(s) // len:5 cap:5 0xc00005c050 [0 1 2 3 4] s2 := s[:2] showSliceInfo(s2) // len:2 cap:5 0xc00005c050 [0 1] s3 := s[3:] showSliceInfo(s3) // len:2 cap:2 0xc00005c080 [3 4] s4 := append(s2, s3...) showSliceInfo(s4) // len:4 cap:5 0xc00005c050 [0 1 3 4] showSliceInfo(s) // len:5 cap:5 0xc00005c050 [0 1 3 4 4]
append するスライス(s3)もされるスライス(s2)も、append した結果を入れたスライス(s4)も、参照する配列は元のスライス(s)の参照先と同じです(s3 は3番目以降の要素を切り出しているのでその分ずれた位置です)。
同じ配列が書き換わるので s に影響が出るのは当然ですね。
対策後
s := []string{"0", "1", "2", "3", "4"} showSliceInfo(s) // len:5 cap:5 0xc00005c050 [0 1 2 3 4] s2 := s[:2:2] showSliceInfo(s2) // len:2 cap:5 0xc00005c050 [0 1] s3 := s[3:] showSliceInfo(s3) // len:2 cap:2 0xc00005c080 [3 4] s4 := append(s2, s3...) showSliceInfo(s4) // len:4 cap:5 0xc000016080 [0 1 3 4] showSliceInfo(s) // len:5 cap:5 0xc00005c050 [0 1 2 3 4]
append するスライス(s3)もされるスライス(s2)も、参照する配列は先ほどと同様に元のスライス(s)の参照先と同じです(s3 の位置のずれについては同上)。
ところが、append した結果を入れたスライス(s4)は異なるアドレスになっています。 これは先ほどスライスの性質を見たときと同じ挙動です。
そうなるのは、s2 の容量が 2 であり、s3 を append するだけの空きがないためです。 append 時に容量が足りなければ自動的に拡張されますが、その際に新たな場所に配列が用意されるのです。
s4 と s の裏にある配列は異なるものとなり、s に影響することがないというわけです。
Goでスライスの中身を消す方法
モバイルアプリのサーバ側を Go で書いていて、スライスをクリアしたい箇所が出てきました。
Go をちょっと使ってはしばらく使わなくなる間に記憶が抜け落ち、スライスの使い方については公式 Wiki の SliceTricks を毎回参照しますが、なぜかクリアする方法が書かれていないので調べました。
これに近い別ページを以前にブックマークしていたことすら忘れていました…。 もう忘れないように、また、上記ページが消えてしまっても困らないように、自分でここにメモしておきます。
操作による要素数や容量の変化を記しているので、消し方だけでなくスライスの性質自体も掴めると思います。
確認用の出力を行う関数
func showSliceInfo(s []string) { fmt.Printf("len:%d cap:%d %p %v\n", len(s), cap(s), s, s) }
nil を使う方法
s := []string{"one", "two", "three"} showSliceInfo(s) // len:3 cap:3 0xc000060150 [one two three] s = nil // クリア showSliceInfo(s) // len:0 cap:0 0x0 [] s = append(s, "four") showSliceInfo(s) // len:1 cap:1 0xc000010230 [four] s = s[:3] showSliceInfo(s) // panic: runtime error: slice bounds out of range [:3] with capacity 1
簡易スライス式を使う方法
s := []string{"one", "two", "three"} showSliceInfo(s) // len:3 cap:3 0xc00005e000 [one two three] s = s[:0] // クリア showSliceInfo(s) // len:0 cap:3 0xc00005e000 [] s = append(s, "four") showSliceInfo(s) // len:1 cap:3 0xc00005e000 [four] s = s[:3] showSliceInfo(s) // len:3 cap:3 0xc00005e000 [four two three]
完全スライス式を使う方法
s := []string{"one", "two", "three"} showSliceInfo(s) // len:3 cap:3 0xc000098150 [one two three] s = s[:0:3] // クリア showSliceInfo(s) // len:0 cap:3 0xc000098150 [] s = append(s, "four") showSliceInfo(s) // len:1 cap:3 0xc000098150 [four] s = s[:3] showSliceInfo(s) // len:3 cap:3 0xc000098150 [four two three] s = s[:0:0] // クリア showSliceInfo(s) // len:0 cap:0 0xc000098150 [] s = append(s, "five") showSliceInfo(s) // len:1 cap:1 0xc000096250 [five] s = s[:3] showSliceInfo(s) // panic: runtime error: slice bounds out of range [:3] with capacity 1
Dart/FlutterのローカルDBの比較
モバイル以外にも対応したローカル DB を使いたかったので、複数のパッケージを調べてみました。
Hive を特に詳しく調べたため、そこだけ情報量が多めです。
2022年12月補足(結論)
記事を書いたときは Isar に注目していましたが、現在は Drift に落ち着きました。
ややこしそうな印象を受けて試さずにいて、しばらく後に再び気になったときに触って良さに気づいたので、もっと早く使えば良かったと思いました。
イチオシです。
- 高い機能性、型安全
- あらゆる場所で使われている SQLite なので非常に堅牢(参考記事)
- この一点だけを見ても Isar のような個人開発のデータベースは比較にならない
- SQLite の最新バージョンを利用できる
- 既に持っている RDB / SQL の知識を活用できる
- RDB なので高度な操作も自在にできる
- Flutter Favorite に選ばれている
- Flutter のドキュメントの一部である Happy paths recommendations で Hive と並んで紹介されている
- Stream 社がスポンサーになっていて継続性などに不安がない
などが理由です。
クエリビルダ、データのクラスなどがやや難解ですが、理解すると「最高!」と思えるようになります。
SQL に抵抗感のない方には強い力となるでしょう。
※単純なデータなら shared_preferences か Hive で事足ります。用途に合わせて選びましょう。 ※Isar も 4.0.0 以降で SQLite がサポートされるようです。
sqflite
- Android / iOS
のみ対応 - macOS にも対応(← 2020/3/3 追記)
- 2019/12 の v1.2.0 で対応済
- Windows と Linux でもちょっとした記述を足すだけで使用可能(← 2020/7/31 追記)
- 手順は こちら
- Web 未対応
今後対応プラットフォームは広がるはず(2021/4/5 現在、もう Web 以外対応済み)- サードパーティだが、主要なパッケージなので対応していくと思われる
- 急ぎでなければ待てば良い
作者さんが慎重に検討している様子が伺えます。
慎重さを欠いて急いで対応してしまうより安心感があります。
idb_sqflite
- おそらく sqflite の Web 対応版(IndexedDB)
- デスクトップにも対応(?)
shared_preferences
- NoSQL
- Web 対応済み
- macOS も対応していると思われる(2020/3/3 追記)
- 2019/12 の v0.5.5 で対応済
デスクトップは不明(2021/4/5 現在、全プラットフォーム対応済みと思われる)- GitHub の Issues が無効化され、Projects もほぼ使われていないので、状況がわかりにくい
- シンプルな KVS でしかない
- 読み書きのメソッドが用意されていない型では JSON シリアライズが必要
- シリアライズできるようにするためのコードを手動か自動で作っておかなければならない
- トランザクションの機能がない
Flutter チームによるパッケージなので、Flutter 本体が正式サポートするプラットフォームを増やせばこのパッケージも対応範囲を広げていくことが予想されます。(対応済み)
Realm
- NoSQL
- SQLite などを用いない独自のデータベース
- MongoDB とのリアルタイム同期(2021/1/9 追記: 大きな特徴なのに忘れていた…)
- 公式 SDK が出たら Firestore の代替になりそう
- パッケージが二つ存在する
- realm
Web にも対応デスクトップはおそらく未対応公式ではなく個人による開発と思われるパッケージのスコアが低くて採用対象にならない- 2021/4/1 に developer preview が公開 ⇒ 後述
- flutter_realm
- Web にも対応
- デスクトップはおそらく未対応
- 公式ではなく個人による開発と思われる
- まだ v0.2.2
- 活発に開発されている様子がない(最後が半年前とか)
- ドキュメントも未整備
- メソッドの説明などが不十分どころか書かれてすらいない
- もう結構できているように見えるという感想もネット上にはあった
- おそらく使った感想ではない
- realm
- リレーションシップ、トランザクション
- 公式のパッケージはないので Dart / Flutter のことではないが、他の言語等の版では対応している
- Flutter を含む新たなプラットフォームや言語への対応は 2020 年 8 月以降
ロードマップ8 月以降に開発開始だとすれば、かなり先になりそう- 進展があり(2021/1/9 追記)
- "we have approved a Dart/Flutter SDK preview."
- プレビュー版の開発を始めることが approve されたのか、もうプレビュー版が出来上がって approve されたのか、どちらなのか不明
- "we have approved a Dart/Flutter SDK preview."
ネイティブアプリ開発では人気高いようです。
公式 SDK が出たら使ってみたいです。
すぐにそのときが来るとは思えないので、今のところは別のものを使っておくのが良いでしょう。
2021/4/5 追記
package:realm のほうは以前は個人名で公開されていたと思いますが、4/1 に同じパッケージ名で Realm 公式として developer preview になりました。
まだ実用段階ではありませんが、今後はこの公式のほうを追うのが良いです。
developer preview では、Flutter 同梱の Dart SDK 2.12 は使えない、リモートとの同期機能が未実装、といった制限が多数あるので、試すならドキュメントをしっかり読みましょう。
Drift
Moor から Drift にリネームされました。
- ORM
- SQLite をラップして抽象化したもの
sqflite を内部で使っている- それなのになぜか sqflite より先に Web 対応完了している
- 訂正
- drift_sqflite で sqflite を使うこともできる
- Android の Room に似ているので、その名前を反転したらしい
- Web / デスクトップ / Dart にも対応
- 2.9.0 で Web サポートが stable になった
- ドキュメントがしっかりしている
- 継続的に開発されている
- Android / iOS で OS に組み込まれている古い SQLite の代わりに最新のバージョンを利用できる
- pubspec.yaml で sqlite3_flutter_libs の使用を宣言するだけ
- データを扱うのに必要なコードを生成しておかなければならない
- 自動生成による大きな利点があるのだと思うが、個人的にコード生成系は好まないので必須なら辛い
- ⇒ 使ってみると便利だった
- クエリビルダが難しいが、使わずに取得等のメソッドを SQL から生成 することもできる
- これすごい!!
- 必要になるパッケージはやや多い(drift, drift_dev, build_runner など)
- SQLite なのでトランザクションなどにはもちろん対応
- マイグレーションとそのテストを補助する機能が追加された
moor_flutter | Flutter Package
Hive
注意:
作り直しが検討されていて従来の Box と非互換になります(Isar という別パッケージ)。
元のパッケージはメンテナの人が管理していくことになったため、安心して継続利用できます。
後述の「Isar」をお読みください。
Isar ベースに変えることが 検討 されています。
- NoSQL(KVS)
- モバイル / Web / デスクトップ / Dart と幅広く対応
- ネイティブへの依存がない
- 独自形式
- ドキュメントがしっかりしている
- 簡単、わかりやすい
- shared_preferences に似た KVS だが、もう少し高機能
- 何でも保存可能
- ただし、
List/Map/DateTime/Uint8List以外はアダプタが必要
- ただし、
- 何でも保存可能
- shared_preferences に似た KVS だが、もう少し高機能
- 継続的に開発されている
- SQLite や Shared Preferences より 高速 (らしい)
- ベンチマークはバイアスをかけることもできるので単純には信用できない
- 通常の Box なら値をメモリにキャッシュ済みなので速いのはわかる
- shared_preferences も読むのは同じ理由で速い
- 書き込みも速いのはなぜ…?
- 画像等のバイナリファイルも保存可能
- リレーションシップに対応
- RDBMS のリレーションシップのイメージで見るとちょっと違うかも
- トランザクションは 非対応
- データを扱うのに必要なコードを生成しておかなければならない
- shared_preferences では生成した上で
json_encode()も必要だが、こちらは生成のみで OK
- shared_preferences では生成した上で
- SQLite のほうが適している場合がある
- 複雑なリレーションシップが必要な場合
- 大量のデータをフィルタリングする必要がある場合
- フィルタリングは
where()- Box から取り出した
valuesはIterableなので次のように絞り込めるuserBox.values.where((user) => user.name.startsWith('s'));
- Box から取り出した
- キーの順にソートされる
- Box と LazyBox
- Box
- オープン時にデータがメモリにキャッシュされる
- なので
awaitなしでデータにアクセスできる
- LazyBox
- キーのみがキャッシュされ、値はアクセスしたとき
- 大きな Box ではこちらのほうがメモリにやさしい
- Box
- 暗号化
- 通常は暗号化されない
- 例えば Web は IndexedDB なので開発者ツールで確認できるが、キーも値もそのまま見える
generateSecureKey()で生成した暗号化のキーをopenBox()のencryptionKeyという引数で渡す- データのキーは暗号化されない
- 暗号化のキーは flutter_secure_storage 等で安全に保管する必要がある
- 機微なデータはそもそもデバイス上に保存すべきではない(と思う)
- 通常は暗号化されない
- Compaction
- Hive は追加のみのデータストアなので
.hiveファイルは大きくなっていく- 削除したときもその情報が「追加」される
- 不要なデータを処分して無駄をなくすことができる
- デフォルトでは、削除回数が60回を超えてエントリに対する削除率が15%を超えたタイミング
- Box オープン時に条件を渡して変更可能
- 自分で
box.compact()を実行して行うことも可能
- Hive は追加のみのデータストアなので
Isar
Hive v2.0 として提案されましたが、Isar という別パッケージとして進められることになりました。
2020/3/3 追記
- Dart FFI と Rust の C interop を使って書き直される
- 速度向上とメモリ使用量の抑制が期待できる
- 作者がプロトタイプで試したところ好感触
- データを楽にフィルタリングできるクエリ機能が追加される
- ベースとなる技術が変わるので v1.x と非互換になる(API だけでなく Box も)
- v1.x のブランチも継続されてバグ修正等が提供される予定
- Hive はまだ若い段階なので、大きく変えるなら今だという決断
- その後に変更があれば自動マイグレーションできるようにしていく
互換性がないのは残念で、v1.x を使っているユーザにとっては不安なところです。
しかし作者さんはしっかりとした考えを持っていて、理解・賛同できるものでした。
Hive は v1.x でも十分に速いですが、更に高速化して便利な機能も追加されるなら大変期待できます。
Rust を使うというのもなんだかワクワクしますね。
応援したいと思います。
注意:
少し 制限 があります。
2020/6/16 追記
v2 を新たなパッケージにして v1 のメンテに誰かが協力する案が出てきました。
少し不安が減りますね。
2020/7/31 追記
Isar という名前で進められていることが3週間ほど前に明らかになりました。
完全に別のパッケージとなります。
Hive のほうのメンテナンスは既に権限が協力者に与えられました。
2021/4/5 追記
1 月にアルファ版がリリースされました。
2/15 には「数週間内に beta 版」と 作者が言っていて 3 月に v0.1.0 が出たので、それが beta 版だと思います。
3 月下旬に追加された Inspector(中身を確認できるツール)が便利そうで、大変期待できます。
1 ~ 2 ヶ月後に stable になるそう です。
ObjectBox
- NoSQL
- Web は非対応(?)
- GitHub の Issues や Projects に情報無し
- example フォルダ内にも無し
- Dart 対応
- 「JS」の表記はない
- デスクトップには対応(?)
パッケージのページには書かれていないがサンプルがある
- パッケージのスコアはそこそこ
- この記事を書いている時点で 85
- Popularity が 70 と低めで、Health と Maintenance は 100
- この記事を書いている時点で 85
- dart:ffi が使われている
- リレーションシップに対応
- Hive では
HiveListという型にする必要があるが、そういう準備なく使えるかもしれない- Flutter 以外のモバイル向けの断片コード(公式ページ内 にあるもの)しか見ていないので推測
- Hive では
- トランザクションにも対応
- 「ACID properties and Multiversion Concurrency Control provide you with safe transactions and parallelism.」と書かれている
- 簡単そう
- パッケージのページなどにあるコードを見た印象では簡単
- 他の NoSQL に似た使い方で取っつきやすそう
Flutter のみのものではないので、以前からの洗練されてきた仕様や機能性が期待できます。
また、もともと慣れている人には嬉しいですね。
Web にいつ対応するのか気になるところです。
2021/5/20 追記
二日前に最初の stable 版である 1.0 がリリースされました!
記事を書いたときに気づいていませんでしたが、デバイス間やクラウド/オンプレサーバとの間でデータを 同期する機能(おそらく有料)もあるようで、なかなか良さそうです。
また、Dart/Flutter 専用ではなくて複数の言語で使えることや、パフォーマンスが良いことも魅力です。
今後のローカル DB 選定では有力候補の一つになりそうです。
sembast
@mirock0606 さんに情報をいただいて調べたので追記します。
- NoSQL(KVS)
- IndexedDB、Datastore、Web SQL、NeDB 等にインスパイアされたもの
- WEB や Dart(Native / JS)に対応
- ピュア Dart
- デスクトップはおそらく対応
- macOS は @mirock0606 さんが確認済み
- パッケージのスコアは高い
- sqflite、idb_sqflite と同じ作者
- idb_sqflite で使われている idb_shim に依存している
- 指定した
.dbファイルに保存、 オープン時にメモリにキャッシュ、自動 Compaction- Hive に似た仕組み
- ファイル内の形式は JSON
- 保存できるデータの型
- キー:
int/String/double - 値:
String/intかdouble/Map/List/bool/null
- キー:
- トランザクション対応
- sqflite のトランザクションに見た目が似ている
- リレーションシップは不明
- フィルタリング
- これは魅力的
- 例:
Finder(filter: Filter.greaterThan('name', 'cat'), sortOrders: [SortOrder('name')])
- 例:
- これは魅力的
- 暗号化対応
- DB のインスタンスを
put()やget()のたびに渡すawait store.record('title').put(db, 'hoge');- sembast のストアを用意してそれを使って実行するにも関わらず sembast の db をわざわざ渡す必要があるのは少し残念
作者が同じせいか、sqflite にトランザクションやフィルタリングの機能を加えて便利にした印象です。
特にフィルタリングに魅力を感じましたし、対応プラットフォームが広めなのも魅力です。
保存できる型が限られているのが残念です。
JSON シリアライズして保存すると JSON の文字列でフィルタリングすることになるのかなと思います。