学習やアウトプット等活動の記録(随時更新 → 終了)
活動した実感があまりないので、記録して振り返る。
- 短時間でやったことでも「勉強したな」と思えたものは記録。
- 時間をかけても身についた実感がないものは記録外。
- 学習時に使ったツールは思い出し用に記録。
- コントリビューションは Issue を立てるだけでも記録。
2020年4月中旬
半年近く更新したが、10日ごとに振り返るのがなかなか辛かったので止めた。
学習等は続ける。
2019 年 10 月
下旬
- DDD
- 「WEB+DB PRESS Vol.113 体験 ドメイン駆動設計」を読んだ
- 「実践ドメイン駆動設計」を少しだけ読んだ
- DDD(Dart/Flutter)
- Go
- 業務で Firebase の Admin SDK を調査・使用(Authentication)
- ポインタについて曖昧なところを復習
- 勉強会
月末最終出勤。
2019 年 11 月
上旬
中旬
下旬
- DDD(Dart/Flutter)
- Go
- IntelliJ 系の IDE の diff 機能を呼び出すツールを作成
- 「Network Programming with Go | Udemy」 の大半を学習
- 「こんなデータベース用ライブラリを誰か作ってほしい(Go)」 投稿
- sqlp の見直し、issue 上げ
- gRPC(Go)
- 機械学習
- 以前に見た「Machine Learning with Javascript | Udemy」を見直しつつメモ
- 低レイヤ
- 勉強会
2019 年 12 月
上旬
中旬
- gRPC(Go, Dart)
- 「DartでgRPCを使う」 投稿
- dart_grpc_examples 公開
- protoc-gen-doc 初使用
- Flutter
- Dart
- Go
- GC の学習
- 「これさえ見ればGoのポインタがわかる!というリンク集」 投稿
下旬
- Flutter
- 多言語対応の調査
- flutter_ddd のリファクタリング(ダイアログなど)
- flutter_remote_piano
- サーバを Dart で書き直し
- Web 対応
- 多言語対応
- コード整理、公開
- 「[Flutter] package:provider の各プロバイダの詳細」 およびサンプルの更新(v4.0.0 対応)
- Dart
- dart_grpc_examples Web 改善・更新(サンプル追加など)
- piano_server 公開
- dart2native 初使用
- stagehand 初使用
- Go
- 機械学習(Go)
- gonum による Logistic Regression の実装
- ツール
- Circle CI による dart2native での各プラットフォーム向けビルド(断念)
月末退職。
2020 年 1 月
上旬
- 機械学習(Go)
- gonum による Logistic Regression の実装(完了)
- 機械学習
- 「ゼロから作るDeep Learning」を読んだ
- Protocol Buffers
- 公式ドキュメント 全体を確認
- 「.protoファイルのアップデートにおける注意点まとめ(protobuf)」 投稿
- Flutter
- Navigation/Routing、画面遷移アニメーション の理解
- Cookbook を一通り見直し
- 勉強会
中旬
- Dart/Flutter
- 「遠隔演奏できるピアノアプリをFlutterとgRPCで作った」 大幅更新
- Service Worker 対応の確認(ホーム画面に追加)
- WebSocket のお試し
- Flame のお試し
- flutter_blue の調査(少し)
- 「The Complete 2020 Flutter Development Bootcamp with Dart | Udemy」 開始・修了
- Go
- goroutine や それを使ったパターン を復習
- 機械学習
- 「ゼロから作るDeep Learning」 読書
- 低レイヤ
- 「低レイヤを知りたい人のためのCコンパイラ作成入門」を途中まで読んだ
- コントリビューション
下旬
- Flutter
- 基礎見直し(Element/RenderObject, BuildContext, Key など)
- アプリ開発開始
- 低レイヤ
- 「低レイヤを知りたい人のためのCコンパイラ作成入門」の続きを読んだ
- コントリビューション
2020 年 2 月
上旬
前月の下旬からアプリ開発を進めているので学習等は少なめ。
- Dart/Flutter
- Flutter
- Navigator/Routes の学習(この動画 素晴らしい)
- Hive の細かな使い方の調査
- 「Flutter - Flutter internals」 再読(3分の1ほど)
中旬
- Flutter
- 円を描くライブラリを作りながら CustomPaint について学習
下旬
- Flutter
- 「Flutter - Flutter internals」 読み忘れていた続き部分
- 新しい animations パッケージの機能を ひととおり試用
- 円を描くライブラリを作りながら CustomPaint, Shader, Gradient, MaskFilter 等について学習
- ライブラリのために SizedBox, Stack, Positioned 等の構造を調査
- ParentDataWidget, createRenderObject(), debugFillProperties() など
- 親子間のサイズ取得について調査
- ライブラリのコード を公開(パッケージとしての公開はまだ)
- 勉強会
2020 年 3 月
上旬
- Flutter
- ライブラリ の改良いろいろ
- Inside Flutter を二回読んだ
- Dynamic Links に関する 動画 を視聴
- Notification Listener の 試用
- RenderObject 等の更なる調査
- 子のサイズを指定せずに自動計算されたサイズによって位置を決める方法など
- 新たに始めた活動
- ツール等
- GitHub Pages 初使用(Flutter ライブラリのデモ と リモートピアノ)
- Stack Overflow 初質問
- コントリビューション
- 勉強会
中旬
- Flutter
- InheritedNotifier に追加された サンプル の理解
- Flutter Gallery のコード を見て中国語対応の正しい方法を理解し、リモートアプリに反映
- Navigator/Routes の学習(この動画) 2月上旬に見たものと似た内容
- アプリ初期化のコードを自分用に まとめなおし
- パフォーマンスのベストプラクティスについて 公式ドキュメント で学習
- Widget of the Week のうち把握できていなかったものを全て視聴
- RenderObject と RenderBox の公式ドキュメントを読んでメモ
- Dart
- json_rpc_2 パッケージの調査・試用
- json_rpc_2 の使用例を作成、こっそり 公開
- Go
- リモートアプリの未公開だった Go 版サーバ を公開
- 汎用技術
- JSON-RPC 2.0 の仕様 の一読・把握
- コントリビューション
- 勉強会
- DDDオンライン勉強会 「集約・境界付けられたコンテキスト」 質疑部分のみ視聴
下旬
- Flutter
- ツール
- DataGrip 使用開始
- 勉強会
- DDDオンライン勉強会 「設計の基本原則"高凝集・低結合"とアーキテクチャ」 途中参加&ながら見
- 他
- Stack Overflow の回答頻度を少し上げた
2020 年 4 月
上旬
- Go
- JWT 関連の調査
- Go での JWT の扱い方
- gRPC と JWT を組み合わせる方法(gRPC の Interceptor / middleware)
- Logger パッケージの調査(logrus / zap / glog など)
- JWT 関連の調査
- CS
- アルゴリズムの復習
- データ圧縮方式
- セキュリティ技術の仕組み(暗号/復号、署名、証明書など)
- アルゴリズムの復習
- コントリビューション
- 勉強会
.protoファイルのアップデートにおける注意点まとめ(protobuf)
Protocol Buffers には様々な用途があるようですが、個人的には gRPC での利用を考えています。 昨年末には Go や Dart/Flutter で gRPC を扱う方法を調べ、使っていけそうだと感じました。
そのときに記事にまとめて Qiita へ投稿しましたので、興味のある方はご覧ください。
使い方を概ね把握しても、プロトコル定義ファイル(.proto)で一度定義した message を将来変えたくなったときにどうするのかを知らないまま本格的に使い始めるのは不安があります。 前もってアップデート時の注意点を把握し、備忘のためにメモしておくことにしました。
免責
次のことを理解した上でご覧ください。
- 本記事は、忘れてもさっと復習できるようにまとめているだけです。網羅できていない可能性もあります。
- 公式ドキュメント(主に proto3 の Language Guide) を基にしていますが、その更新を常に反映していくとは限りません。
用語
気をつけるポイント

既存のフィールド
新たなフィールド
- フィールドを追加すれば message の形式が変わるが、古いコードでシリアライズされた message は新たなコードでパースできる
- 同様に、逆(新しいコードで生成された message を古いコードでパース)も可能
- 新たに追加されたフィールドは
Unknown field(付録参照)- 古いバイナリではパース時に単に無視されるので、既存コードへの影響を気にする必要はない
- デフォルト値を考慮
- 新しいコードでも古いコードで生成された message と適切にやり取りできるよう、要素のデフォルト値について考慮すること(付録を参照のこと)
フィールドの削除
- 削除したフィールドの番号が再利用されない限り OK
- message をバイナリ形式にしたときにフィールドを特定するための「ユニークな」番号
- ユニークでなければならないのに再利用してしまえば当然問題が生じる
- 番号の再利用を防ぐ方法
- 再利用を防ぎたい番号や範囲を
reservedで指定する- 使おうとしてしまったときに警告が出て気づける
- 番号だけでなく名前で指定することもできるが、番号と名前を混ぜて指定することはできない
-
maxというキーワードで番号の最大値までを指定することもできる
- 削除する代わりにフィールドをリネーム(
OBSOLETE_という接頭辞をつける等)する
- 再利用を防ぎたい番号や範囲を
- 削除の前には
[deprecated=true]の オプション を使うと良いかもしれない
reserved 2, 15, 9 to 11, 40 to max; reserved "FOO", "BAR";
将来を考えた附番
- サイズを意識
- エンコードすると
1~15は 1 バイト、16~2047は 2 バイトになる(番号と型を含めて) - 頻繁に使う message 要素には 1 ~ 15 を使うのが良い
- 使用頻度の高い要素が将来追加されたときのために 1 ~ 15 の範囲にいくらか空きを残しておくこと
- エンコードすると
int32 / uint32 / int64 / uint64 / bool
- どれも互換
- 前方/後方互換性を壊さずに相互に入れ替えることが可能
- ただし、ビット数が足りなければ切り詰められる(64 ビットの数が int32 として読まれたときなど)
sint32 と sint64
- 互換だが、他の整数型とは非互換
string と bytes
- bytes が有効な UTF-8 である限り互換
埋め込まれた message
- message のエンコードされたバージョンが bytes に含まれていればその message と bytes は互換
fixed32 と sfixed32
- 互換
fixed64 と sfixed64
- 互換
enum
- int32 / uint32 / int64 / uint64 と互換だが、サイズが合わなければ切り詰められる
oneof
複数のフィールドがあってもそのうちの一度に一つしかセットすることがない場合、oneof を使うとメモリを節約できる。 しかし、アップデートにおいては注意が必要な点が多い。
- フィールドを
oneofに追加したりoneofの外に移動したりする場合- message がシリアライズされてパースされると情報が一部失われることがある(一部のフィールドがクリアされる)
- 既存の
oneofに入れるのは安全でない
- 既存の
- ただし、一つのフィールドを新たな
oneofに移すのは安全 - 一つしかセットされないのがわかっているなら複数フィールドを移すのも安全
- message がシリアライズされてパースされると情報が一部失われることがある(一部のフィールドがクリアされる)
oneofのフィールドを一つ消して追加し直す場合- message がシリアライズされてパースされると、セットされている
oneofフィールドがクリアされることがある
- message がシリアライズされてパースされると、セットされている
oneofを分離/統合した場合- 通常のフィールドを移動したときと同様の問題が起こる
map
map<key_type, value_type> map_field = N;
これは wire フォーマット上では下記に相当する。
message MapFieldEntry { key_type key = 1; value_type value = 2; } repeated MapFieldEntry map_field = N;
map をサポートしていない実装でも扱えるので、そういった言語にも対応させられるかという心配は無用。
.proto ファイルの変更
定義の記述を別ファイルに移す(下記例では old.proto から new.proto へ)とき、元のファイル(old.proto)で import public を使って新たなファイル(new.proto)を読み込めば
クライアントでは読み込み対象を変えずに済む。
new.proto
// old.proto に書かれた定義をすべてこのファイルに移動
old.proto
// どのクライアントもこのファイルをインポートしている import public "new.proto"; import "other.proto";
client.proto
import "old.proto"; // old.proto と new.proto で定義したものは使えるが、other.proto の定義は使えない
なお、protoc コマンドでコンパイルするとき、-I や --proto_path で指定したディレクトリがインポートファイルの検索対象になる(指定しないと実行時のカレントディレクトリ)。
それを使ってプロジェクトのルートを指定し、インポートで完全修飾名を使うのが良い。
付録
デフォルト値
- string
- 空文字列
- bytes
- 空バイト列
- bool
- false
- 数値型
- 0
- enum
- 定義されている最初の値(= 0)
- message フィールド
- セットされない(言語依存)
- 詳細は generated code guide を参照のこと
- repeated フィールド
- 空(各言語の空リスト)
- スカラー型のフィールド
- パースされると、フィールドにデフォルト値が入れられていたのか何も入っていなかったのか区別できないことに留意しておくこと
- 例えば bool 型の場合、false のときの振る舞いがデフォルトの振る舞いにもなる
- それが困るなら bool 型は避けること
- パースされると、フィールドにデフォルト値が入れられていたのか何も入っていなかったのか区別できないことに留意しておくこと
proto2 と proto3
- proto1 は無い
- 今は proto3
- proto2 と完全互換ではない
- proto2 もサポートは続けられるが、使いやすくて対応言語も多い proto3 のほうが良い
- proto3 で proto2 の message 型を使うこともその逆も可能
- ただし proto2 の
enumを proto3 で直接使うことはできない- proto2 の message で使い、それを proto3 でインポートするのは OK
- ただし proto2 の
syntaxの指定を省略すると proto2 とみなされる
syntax = "proto3";
proto3 での変更点
requiredとoptionalは廃止repeatedのpackedがデフォルトでtrueなので指定不要- proto2 ではエンコーディングを効率的に行うために
[packed=true]のオプションが必要だった
- proto2 ではエンコーディングを効率的に行うために
enumの先頭要素は0- 先頭要素でなければならないのは proto2 との互換性のため(proto2では最初の要素が常にデフォルト)
Unknown fieldsの扱いが v3.5 で変わった
上記は一部です。 全体的な変更点は次の記事が参考になると思います。
*1:gRPCのシリアライゼーション形式をJSONにする - Qiita
*2:ドキュメントには Java の @Deprecated のことしか書かれていないので他の言語については不明・未確認。
こんなデータベース用ライブラリを誰か作ってほしい(Go)
Go2 Advent Calendar 2019 の 6 日目の記事です。
Go の database/sql って使いにくくないでしょうか。
二年ちょっと前にもっと楽にできないかなと思って調べました。
欲しかったもの
database/sqlを使いやすくしたもの- ORM は要らない
- ただし、SELECT と INSERT は楽をしたい
ORM を必須とする人もいると思いますが、そのときは直に SQL 文を書きたかったので、それに合ったライブラリだけを試しました。
試したライブラリ
というわけで gorp を選び、そのときに書いた記事が下記二つです。
gorp の問題点
しかし、大きな問題を見つけました。 なんと gorp は Bulk Insert に対応していなかったのです。(´・ω・`)
一度に INSERT したいデータをスライスに入れて渡すと一応できたのですが、大量のデータだと非常に遅くなってしまいました。 うろ覚えですが、gorp のコードを見てみると 1 データずつ INSERT しているようでした。 *1
自分で改良して貢献するチャンスだと思ったのですが、力不足で無理でした。 gorp のユーザはどうしているのでしょうか。
@mattn さんがつい最近解決されていたことに先ほど気づきました。 話が止まってしまっているように見えますが、gorp に取り込まれるといいなと思います。
Multiple insert · Issue #313 · go-gorp/gorp · GitHub
自分で作りました
タイトルで「誰か作ってほしい」としましたが、実は gorp の問題を早めに諦めて「sqlp」というライブラリを自分で作りました。 *2
database/sql をラップしたもので、なるべく近い使い方になるように考慮しました(大きく異なる部分もあります)。
主な特徴は次のとおりです。
- SELECT で取得したデータが構造体/マップ/スライスに入る
- それをシンプルに書ける
- Bulk Insert できる
- プレースホルダの扱いが楽
作ってしばらく寝かせてから GitHub に置いてもう二年近く経つのですが、ずっと Work In Progress 扱いにしています。
WIP の理由
- ドキュメントが不十分
- README はしっかり書きましたが、コードにコメントがないので GoDoc が裸です。
- テストが不十分
- 泥臭いことをしている
- 実用例が少ない
- 個人で時々使っているだけです。
- 自信がない
- 日頃から業務で Go を使っているわけではなく、致命的な不具合がないか不安です。
- 作った本人が不安に思っているものを誰も使うはずがありませんが、万全だと見せかけるのは無責任です。
- DB 関連はミスの影響度が大きいです。
ドキュメント作成やテストは自分でできますが、残りは他者の協力がないと改善が難しそうです。
希望・期待
- 誰かが同じものをより良く作り直してくれないかな
- 便利だと思われた方はぜひオリジナルより優れた模造品を作ってください。
- 使い方は後半に書きます。
- 誰かが改善に協力してくれないかな(Issues、Pull Request)
- 誰かが見かねて大幅にやり直してくれないかな(Fork して新たに)
database/sqlが同じ機能を持っていたらいいのにな
かなり他力本願ですが、こんな気持ちです。
コードの質などは置いておいて、ライブラリのアイデア自体は悪くないと思っています。 よろしければ触ってみてください。
この記事の動機
上記のような期待は持っていても、なかなか記事にまでしようと思い立てませんでした。
しかし、今年の Go の Advent Calendar ではここまで一週間も経っていない間に関連する記事がいくつかあり、自分のアイデアを伝えるのも良いかなと思いました。
Go5 アドカレ 1 日目
Goではどんなライブラリがデータベースにアクセスするときにベストか考える - ぷらすのブログ
クリックで開閉
database/sql ではスキャンしたデータを構造体にマッピングする機能はありません。マッピングするにはスキャンしたデータ一つ一つごとに引数でを渡す必要があります。
実際に使う上では、少々面倒くさいと感じる人が多いと思います。そういった場合はサードパーティのライブラリを使用します。
それでは、サードパーティのライブラリにどのような機能を求めているでしょうか? いくつか考えられるものを挙げてみました。
Go3 アドカレ 2 日目
2019年の GORM 動向 | ザネリは列車を見送った
クリックで開閉
今までGoでの開発を3社経験したが、全社Webアプリケーションフレームワークに Gin、ORM に GORM という構成だった。
スター数や知名度などからメジャーな ORM 感を醸し出しているが、使えば使うほど粗が見えてしまい、
次は別の DB ライブラリを選択したほうがいいのでは?いやそもそも素の database/sql だけで十分なのでは?
いやいやどうせ SELECT した結果を struct にバインドするような処理は必要だから、薄い DB ライブラリは欲しくなるのでは?と考えを巡らせる事がある。
Go4 アドカレ 5 日目
Go 言語で初めてのライブラリ開発 - It's a Piece of Cake
DB 操作のしにくさを感じて便利なライブラリを求めている人が他にもいるんだなと思いました。 また、3 つ目のライブラリ開発の記事ではライブラリを作った経緯などが書かれていて、自分も記事にしようという後押しになりました。
工夫したこと
- refrect
- 未知の構造体型をメソッドで受け取ってフィールドに値を入れるために
reflectパッケージを使っていますが、扱っているものがポインタなのか何なのかわからなくなることが多かったため、PtrValueOf()など ラップした関数を用意 して名前でわかるようにしながら使いました。
- 未知の構造体型をメソッドで受け取ってフィールドに値を入れるために
- インタフェース
sqlp.goというファイルにある sqlExecContext() 等のメソッドは、通常はdatabase.sqlのDB、トランザクションならTx、というようにレシーバを変えて共通使用する必要がありました。まさに Structural Subtyping が生きるところだと思い、やってみるとスッキリさせることができました。
- エラー出力
- どこでエラーが起きたかわかりにくかったので、スタックトレースの情報を加工 してファイルパスと行番号を出力するようにしました。(*4)
sqlp の使い方
README がほぼ全てですが、日本語の情報がないのでここにまとめておきます。
DB オープン/クローズ
db, err := sqlp.Open("mysql", "user:pw@tcp(host:3306)/dbname")
db は *DB という型で、その構造体の SqlDB というフィールドに database/sql の DB のポインタを持っています。
必要なら取り出して使うことができます。
もし既に *sql.DB があるならそれを使って Init() で sqlp の*DB 型に変換できます。
sqlDB, err := sql.Open("mysql", "user:pw@tcp(host:3306)/dbname") db := sqlp.Init(sqlDB)
使い終わったら db.Close() でクローズしましょう。
INSERT
以下の説明は、次のようなテーブルがあると仮定したものとなります(MySQL の例)。
CREATE TABLE user ( id int(10) unsigned NOT NULL AUTO_INCREMENT, name varchar(32) NOT NULL, age tinyint(3) unsigned NOT NULL, recorded_at datetime DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB;
Insert() では、挿入するデータを構造体に入れてスライスで渡せるようにしていて、一つでも複数でも可能です。
複数データの場合、自動的に INSERT 文の VALUES の後ろにカンマ区切りで指定する形に変換されます。
また、エスケープも自動です。
type tUser struct { Name string Age int RecordedAt mysql.NullTime `col:"recorded_at"` } now := mysql.NullTime{Time: time.Now(), Valid: true} data := []tUser{ {Name: "User1", Age: 22, RecordedAt: now}, {Name: "User2", Age: 27, RecordedAt: mysql.NullTime{}}, {Name: "User3", Age: 31, RecordedAt: now}, } res, err := db.Insert("user", data) if err != nil { log.Fatal(err) } cnt, _ := res.RowsAffected() id, _ := res.LastInsertId() fmt.Printf("Number of affected rows: %d\n", cnt) // Number of affected rows: 3 fmt.Printf("Last inserted ID: %d\n", id) // Last inserted ID: 1
カラム名は、構造体のフィールド名と case-insensitive な比較によって一致するものが自動的に対応付けられます。
カラム名が recorded_at、フィールド名が RecordedAt だと文字の大小を無視しても一致しませんが、タグでカラム名を明示することで解決できます。
3 行を INSERT したのに LastInsertId() の結果が 3 ではなく 1(まとめて追加したうちの先頭行の ID)になっているのは、おそらくドライバがそうなっているからです(go-sql-driver/mysql の場合)。
*5
*6
UPDATE
ORM ではありませんし、UPDATE の WHERE 句が複雑になることもあって自分で SQL 文を書いたほうがいいと思ったため、Update 専用のメソッドは用意していません。
database/sql で操作するときと同様に Exec() 等を使うことになります。
Scan
database/sql の Scan() は引数としてカラム一つずつのための変数を渡さなければならなくて不便に感じたため、そうしなくても構造体・マップ・スライスのどれかに結果を入れられるようにしました。
下記はマップに入れる例です。
rows, err := db.Query(`SELECT name, age, recorded_at FROM user`) if err != nil { log.Fatal(err) } defer rows.Close() for rows.Next() { u, err := rows.ScanToMap() if err != nil { log.Fatal(err) } fmt.Printf("%s: %s yo [%s]\n", u["name"], u["age"], u["recorded_at"]) }
User1: 22 yo [2018-06-24T01:23:45+00:00] User2: 27 yo [] User3: 31 yo [2018-06-24T01:23:45+00:00]
マップとスライスに入れる場合、カラムが数値等の型であっても文字列になる点に注意が必要です。 interface{} 型にしておいて型アサーションして使うことも考えましたが、文字列で妥協しました(理由は覚えていません)。
構造体の場合、INSERT の場合と違ってアンダースコアの有無によってフィールド名とカラム名が異なっていても同じとみなされます。
また、PrepareContext() のような database/sql に存在するメソッドはほとんど用意しているので、SQL 文を先に用意しておいて再利用することや Context でタイムアウト設定やキャンセルをすることもできます。
SELECT
こちらも構造体・マップ・スライスに入れられるようになっています。
Scan() との大きな違いは、複数行ある場合に Next() で行ずつ取り出す必要がないことです。
その分少ないコードで済みますが、大量のデータを一度に取得する際にはメモリにご注意ください。
構造体に入れる場合には次のように書けます。
var u []struct { Name string Age int RecordedAt mysql.NullTime } err := db.SelectToStruct(&u, `SELECT name, age, recorded_at FROM user`) if err != nil { log.Fatal(err) } fmt.Printf("%+v\n", u)
[
{Name:User1 Age:22 RecordedAt:{Time:2018-06-24 01:23:45 +0000 UTC Valid:true}}
{Name:User2 Age:27 RecordedAt:{Time:0001-01-01 00:00:00 +0000 UTC Valid:false}}
{Name:User3 Age:31 RecordedAt:{Time:2018-06-24 01:23:45 +0000 UTC Valid:true}}
]
マップやスライスでは構造体を用意することなく使えるので、ちょっと取得して確認したいときなどには楽です。
u, err := db.SelectToSlice(`SELECT name, age, recorded_at FROM user`)
名前なしプレースホルダ
プレースホルダは独特のものになっています。
名前なしの場合、DBMS(*7)の実装によらず ? を使います。
? 以外($1 など)を使わなければならない DBMS に対応する方法は後述します。
q := `UPDATE user SET age = ? WHERE age IN ?[2]`
?[2] の形式は sqlp 独自です。
この SQL 文は内部的に
UPDATE user SET age = ? WHERE age IN (?,?)
に置換されます。 これに対する値の指定方法は次のいずれも OK です。
db.Exec(q, 11, 22, 33) db.Exec(q, 11, []interface{}{22, 33}) db.Exec(q, []interface{}{11, 22}, 33) db.Exec(q, []interface{}{11, 22, 33}) db.Exec(q, []interface{}{11, 22}, []interface{33})
名前付きプレースホルダ
コロンで始まる名前を使います。
q := `UPDATE user SET age = :age_new WHERE age IN :age[2]` // → UPDATE user SET age = ? WHERE age IN (?,?)
これも先ほどと同じ SQL 文に置換されます。 値の渡し方は名前なしの場合のように自由ではなく、名前(コロンなし)をキーとする interface{} のマップを用います。
res, err := db.Exec(q, map[string]interface{}{ "age_new": 11, "age": []interface{}{22, 33}, })
:age[2] の形式に対しては interface{} のスライスで指定し、その要素数は [] で指定した数と一致している必要があります。
プレースホルダの記号の変換
? 以外を使うことになっている DBMS では、? から変換する関数を用意する必要があります。
ただし PostgreSQL の $1 という形式は sqlp であらかじめ対応しています。
placeholder.SetType(placeholder.Dollar) q := "SELECT * FROM user WHERE name LIKE ? AND age IN ?[2]" u, err := db.SelectToMap(q, "User%", 22, 23)
placeholder.SetType() でドル記号を使うよう指定しているので、次のように変換されます。 *8
SELECT * FROM user WHERE name LIKE $1 AND age IN ($2, $3)
それ以外の記号(そういうものがあるか把握していませんが)も、placeholder.SetConvertFunc() を使って変換用関数を設定すれば対応できるはずです。
例えば、もし <> という記号を使わなければならないとしたら、下記のように書けると思います。
placeholder.SetConvertFunc(func(query *string) { cnt := strings.Count(*query, "?") for i := 1; i <= cnt; i++ { *query = strings.Replace(*query, "?", "<>", 1) } })
おわり
どなたか、もっと良いものを作成されたときにはお知らせいただけると嬉しいです。 また、sqlp を改善して使っていけそうならぜひご協力ください!
明日は @kawasin73 さんです。
*1:Bulk Insert に対応していない DBMS のことを考慮したものなのかもしれません(勝手な解釈です)。例えば SQLite は 3.7.11 でようやく対応したようです。 非対応のときだけエラーにすれば良いのでは、と思いました。
*2:名前は database/sql と sqlx へのオマージュです。末尾の「p」は適当で、「plus」か何かその辺りの頭文字です。database/sql より少し使いやすくしたことを意味します。
*3:CRUD 等の動作のテストを書いていないのは、CI で DBMS を用意する方法がわからなかったからです。モックを用意できるようなので、その方法を検討しようと思っています。
*4:見直してみるとそれを使っていない箇所が多かったので要改善です。
*5:database/sql を直に使って Bulk Insert しても同じ結果でした。
*6:RowsAffected() と LastInsertId() のそれぞれの二つ目の戻り値が常に nil になります。これは作りの問題ですので見直そうと思います。
*7:プレースホルダの記号は DBMS というよりもそのドライバによって異なるものでしょうか。
*8:指定しなくてもドライバの種類を読み取って自動判別すると良いかもしれません。
Dart/Flutterでドメイン駆動設計(DDD)してみた - 実装編
前編である「導入編」の続きです。
まずそちらをざっと一読されることをお勧めします。
ソースコードは本記事投稿後にたびたび改変しており、記事内容との相違があります。ご了承ください。
作るアプリについて(ご注意)
Flutter によるアプリ開発でも DDD の恩恵があるのかを試すことと理解を深めることを目的とするサンプルであるため、アプリとして本来は考慮すべき点をいくつか無視しています。
- データベース操作の効率や確実性にこだわっていない
- メモのタイトルとカテゴリだけを使うときに本文まで取得している等。
- 更新や削除を行った結果の確認も省いています。
- 保存数に制限を設けていない
- 何万件ものメモを保存したときの動作は想定外かつ未確認です。
- エラーメッセージの扱いが不十分
- 補足した Exception のメッセージをそのまま表示しています。
- UI/UX は最低限
- 機能することを優先し、きれいで魅力的な見た目にしようとしていません。
あまりこだわらなくても標準装備のマテリアルデザインのおかげでそれなりの UI になるのは Flutter の良いところですね。
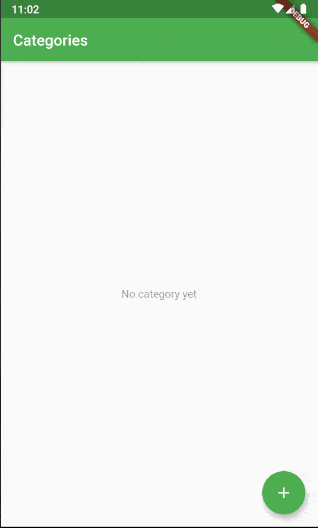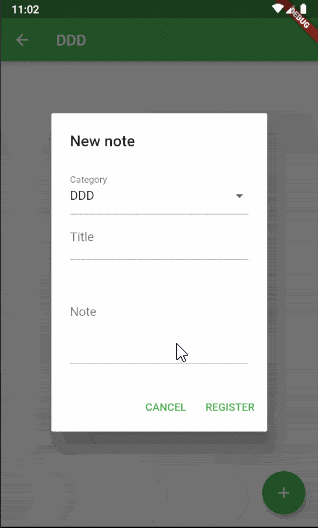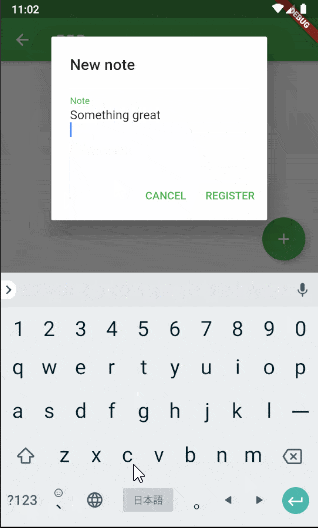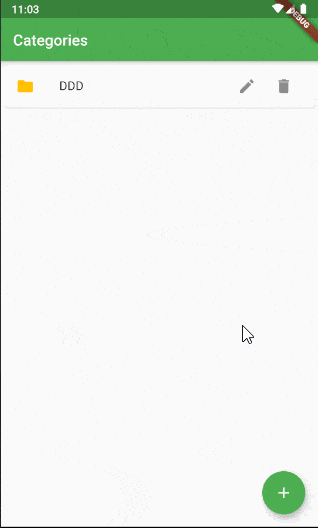
実用について
実装に入っていく前に補足しておきます。
この記事のような設計に関して抽象化の部分をことさらに強調して無駄だ冗長だと否定する人がいますが、設計全体に対して抽象化は一部にすぎないのに全体が無駄かのように全否定していると柔軟性や保守性に欠けるソフトウェアになります。
その逆に、いま必要でないことまで何でもかんでも考慮した設計は過剰だとは思います。
全否定することと完全に抜けのない設計をすることは両極端すぎるので、私は間を取る考えです。
抽象化は必要になったときにすればいいという程度に捉えていて、長期的に継続開発できる、あるいはしばらく間が空いた後に改修するときにも困らない、といったことが自分の目指すところです。
私が実際に何か作るときには、保守しやすさを特に重視しながらこの記事の一部のみを取り入れています。
そこの塩梅は人それぞれなので、考えてみるといいと思います。
値オブジェクト(Value object)
ドメインオブジェクトの一つです。 int のようなプリミティブな型を使うよりも、専用の型を用意したほうが良いという考え方です。
値オブジェクトは多くなりやすいので、「value」というフォルダを作ることにしました。

ボトムアップドメイン駆動設計 では、値オブジェクトを作るモチベーションとして次の二つが挙げられています。
- 存在しない値を存在させない
- 誤った代入を防ぐ
存在しない値を存在させない
class CategoryId { final String value; CategoryId(this.value) : assert(value != null), assert(value.isNotEmpty) { if (value == null || value.isEmpty) { throw NullEmptyException('Category ID'); } } ... }
カテゴリ ID の値オブジェクトです。
コンストラクタにてバリデーション(null や空文字のチェック)も行っています。 これが非常に大事で、間違った値が入ってしまってからその値の使用箇所で検証するのではなく、そういった値がそもそも入ってしまうことを防ぐことができます。 *1
念のために assert() も使っていますが、ここは見直し対象です…。
コンストラクタが不正な値を受け取ると、リリースモードでは if ブロックで例外をスローしますが、デバッグモードではそこに到達する前に assert() で別のエラーが発生するため、モードによって例外の種類やメッセージが異なってしまいます。
値オブジェクトはベースになるものなのでしっかり作っておこうと思ったのですが、assert() しないほうがいいかもしれません。
→ assert() はその後やめました。
誤った代入を防ぐ
String 型のカテゴリ ID を受け取るメソッドがあるとします。
void hoge(String id)
このメソッドにカテゴリ ID 以外の文字列が渡されてもエラーになりません。
一方、仮引数に値オブジェクトを使う場合、CategoryId 型でないものが渡されるとコンパイル時点でエラーになり、誤った代入を防げます。 また、コンパイルより前にも静的解析による警告がエディタに表示されます。
void hoge(CategoryId id)
IDE によっては記述時に引数の情報を表示してくれますが、CategoryId というわかりやすい型名で表示されて String より断然わかりやすくなるという利点もあります。
Dart の名前付き引数
Dart には便利な「名前付き引数」があり、関数/メソッドに値を渡すときに引数名を指定させることができます。
void hoge({String categoryId}) { ... } hoge(categoryId: 'カテゴリ ID の文字列');
しかし、引数名は categoryId になっているものの、型は String のままです。
categoryId と名前指定しながら疲労等によるミスで「カテゴリ 名」を渡してしまってもエラーになりません。
また、カテゴリ ID の形式を検証する機能は String 型には当然ありません。
値オブジェクトを使いつつ、名前付き引数も併用するのが良いと思います。
値オブジェクトのルール
- 状態を不変に保つ
- 同じ値オブジェクト同士で値が等しいかどうかの確認ができる
- 完全に交換可能である(*2)
簡単に言えば、値オブジェクトは String 等と同じ「値」ということです。
String s = 'foo'; // 不変 s.changeTo('bar'); // このようにはできない // 比較できる if (s == 'foo') { // 交換可能 s = 'bar'; }
値オブジェクトが「値」としてこれと同様の振る舞いとなるようにコードを書くことになります。
@immutable class CategoryId { final String value; CategoryId(this.value) { ... } @override bool operator ==(Object other) => identical(other, this) || (other is CategoryId && other.value == value); // == をオーバーライドするにはこのオーバーライドも必要 @override int get hashCode => runtimeType.hashCode ^ value.hashCode; }
これでルールに沿うものになって「値」らしくなります。
こんな風に書くのは煩わしく感じられますが、不変なので「値」が誰かに書き換えられてしまう心配がなくなる等のメリットがあります。*5
等価チェックはどこで行うのか先にイメージできなかったものの、後で結局必要になりました。 箇所は少ないかもしれませんが、不要かもしれないと考えて省かずに必ず実装しておくのが良いと思います。
ルールを守るための改善案
equatable パッケージを使うと自動的に immutable になり、値オブジェクトを作るときのルールのミスを防げる上に、ボイラープレートを減らすことにもなります。 他の方法でもいいですが、記述の揺れや漏れを防ぐ工夫はチーム開発では特に大事だと思います。
エンティティ(Entity)

ドメインオブジェクトの一つで、値オブジェクトに似ているけれど反対のような性質を持つものです。
- 可変
- 同じ属性でも区別される
- 同一性を持つ(*6)
可変であり、何らかの識別子(ID など一意かつ不変のもの)によって区別します。
例えば下記はカテゴリのエンティティですが、カテゴリ名が同じでも同一と判断せず、カテゴリ ID で判断しています(other.id == id のように識別子同士で比較します)。
class Category { // 同一性の判断に用いる ID は不変 final CategoryId id; CategoryName _name; Category({@required this.id, @required CategoryName name}) : _name = name; CategoryName get name => _name; @override bool operator ==(Object other) => identical(other, this) || (other is Category && other.id == id); @override int get hashCode => runtimeType.hashCode ^ id.hashCode; // 可変のフィールドはメソッド経由でしか変更させない void changeName(CategoryName newName) { _name = newName; } }
識別子は変わってはいけないので、それだけは final です。
それ以外のフィールドは必ずメソッド(上のコードでは changeName())を通して変更するので private にし、Getter を用意します。
CategoryName 等のバリデーションはその値オブジェクトのほうにメソッドがあるので、エンティティでは省きました。 *7
永続化
ボトムアップドメイン駆動設計 より:
Entity は同一性に着目するため、ライフサイクルが存在し、データベースやファイル等に永続化されることが多いです。
エンティティが永続化の対象になるようです。 つまり、リポジトリ(後述)が担当するのはエンティティの状態を保存したり取り出したりすることだと思っておけば良さそうです。
可変ゆえの悩み
もし Note が Category のデータを持っていると、次のように Note から Category のメソッドを利用して Category が保持するカテゴリ名を変更できてしまいます。 後ほど集約のところで説明しますが、これはアンチパターンです。
// ダメな例です note.category.changeName('hoge');
このような操作をしないこと!という決まりを開発メンバー間で作っておいても操作しようと思えばできてしまうので、させないよう制限する方法が必要です。
- Note が持つ Category を隠蔽する
- ただし、それを使う範囲からのアクセスのみを許可する工夫が必要です。(*8)
- Note が持つ Category を隠蔽し、複製データを得るための Getter を用意する
- 複製を変更してもエンティティが持つ元のデータに影響が及びません。
- 読み取り専用の値を保持対象にする
- ミュータブルな Category ではなくイミュータブルな CategoryId を持たせれば安全です。
- 通知パターンを使う
- ただし、処理が煩雑になります。( *9)
ボトムアップドメイン駆動設計では、User のエンティティ自体ではなく読み取り専用の UserId のリストを Circle で保持し、更に通知パターンも使っています(上記の三つ目と四つ目の組み合わせ)。 メモアプリでは、通知パターンを使うとややこしくなるので三つ目だけにしました。
集約(Aggregate)
整合性を保たないといけないトランザクションの範囲を一つのまとまりとして表した単位です。 メモアプリでは「カテゴリ」と「メモ」がそれぞれ個々の集約です。
集約には次のような決まりがあります。
- ルートとなるエンティティが各集約に一つだけある(集約ルート)
- 集約ルートのみが集約内の他のドメインオブジェクトを操作可能
- アプリケーションサービスから操作できるのは集約ルートのみ
カテゴリとメモはエンティティを一つずつしか持っていないので、その一つずつが集約ルートです。
集約に含むもの
どうやら値オブジェクトとエンティティだけのようです。 おそらくドメインサービスは含みません。
デメテルの法則
アプリケーションサービスは集約ルートが持つ他のオブジェクトを取り出して操作してはいけません。 デメテルの法則 というものです。
上記リンク先の Wikipedia の記事より:
あるオブジェクトAは別のオブジェクトBのサービスを要求してもよい(メソッドを呼び出してもよい)が、オブジェクトAがオブジェクトBを「経由して」さらに別のオブジェクトCのサービスを要求してはならない。これが望ましくないのは、オブジェクトAがオブジェクトBに対して、オブジェクトB自身の内部構造以上の知識を要求してしまうためである。
先ほどの Note に Category を持たせるアンチパターンはこのことです。 アプリケーションサービス(オブジェクトA)で Note(オブジェクトB)のメソッドを呼んでもいいけれど、Note を経由して Category(オブジェクトC)のメソッドを呼び出すのは NG ということです。
そんな不自然な操作をしないといけなくなっているなら、設計がおかしいと考えられます。 その操作のメソッドを Note に持たせるだけで解決できることもありますので、おかしいと感じたら見直してみましょう。 *10
集約の範囲(整合性の境界)
メモアプリはボトムアップドメイン駆動設計をベースにしたため、単純に「ユーザとサークル」を「メモとカテゴリ」に置き換えて考えることができましたが、自分で集約の範囲を決めることになったら少し難しいですね。
先ほど書いた「整合性を保たないといけないトランザクションの範囲」が集約の決め方の基本だと考えて良いはずですが、それだけでは不慣れな私にとっては判断に不十分です。
例えば、あるウェブサービスで会員登録を行うとき、登録によるボーナスポイント付与までがトランザクションの範囲だったら、会員データ関連とポイント関連が同じ集約に含まれることになるのでしょうか…?
明確に判断できるよう、「実践ドメイン駆動設計」などで理解を深めないといけないなと思います。
ドメインサービス(Domain service)

エンティティに関係するロジックであるけれども、エンティティに実装すると違和感を産むロジックは必ず存在します。
そういったロジックを受け持つものとしてドメインサービスが存在します。 *11
ボトムアップドメイン駆動設計では、ユーザが自身の重複を確認するのは不自然ということで、重複確認のメソッドをエンティティではなくドメインサービスに持たせています。 メモアプリのメモやカテゴリの重複確認も同様にしました。
class NoteService { ... Future<bool> isDuplicated(NoteTitle title) async { final searched = await _repository.findByTitle(title); return searched != null; } }
ドメインサービスに書くか否か
カテゴリ名変更のメソッドについても「カテゴリという無機質なものが自身の名前を変える」という点に違和感を覚えました。 しかし先ほどの「重複の有無を自分に尋ねる」という不自然さとは異質に思えます。
「生物でもないものが自分で名前を変える」ことは擬人化すればどうにか成立しますが、「自分が知らないこと(重複しているかどうか)を自分に尋ねる」ことはどうしても矛盾があるので、その違いかなと考えました。
それでも迷いが消えなかったため、ボトムアップドメイン駆動設計 の下記アドバイスに従って、カテゴリ名変更はエンティティのほうにしました。
ドメインサービスとエンティティのどちらにロジックを記述するか迷ったときはエンティティに記述してください。
ドメインサービスと値オブジェクトのどちらにロジックを記述するか迷ったときは値オブジェクトに記述してください。
ドメインサービスは必要最小限にすることを心掛けましょう。
リポジトリ(Repository)
ドメインオブジェクトに永続化の処理を書くと、その記述ばかりになってしまったりします。 また、ドメインオブジェクト内に直接書くとデータベースに強く依存してしまいます。 そうならないように「リポジトリ」として分けて書きます。
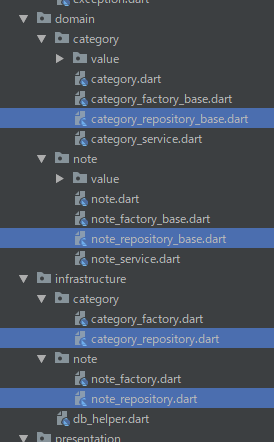
リポジトリを置く場所は 導入編 に書いたとおり 依存関係逆転の法則 によってインタフェースがドメイン層、実装がインフラ層になると考えていましたが、Qiita の記事 のコメントによると実装のほうはどこでも良いそうです。
iDDDを確認したところ、「インタフェースはドメイン層に作る。実装はどこでもいい。インフラ層でもいい(=つまりインフラ層じゃなくてもいいってことですね)」と書いてありました。
これも iDDD 本(実践ドメイン駆動設計)で示されているのですね。 やはりちゃんと読まないと…。
リポジトリの単位
ボトムアップドメイン駆動設計 より:
リポジトリは集約毎に用意します。
整合性の単位が集約ですから、集約に対応するようにリポジトリを定義しておけば変更を過不足なく永続化できるからです。
ということで、メモアプリでは「カテゴリ」と「メモ」のそれぞれの集約分を用意しました。
リポジトリの利用元
松岡さんの記事(「DDDのモデリングとは何なのか、 そしてどうコードに落とすのか」資料 / Q&A - little hands' lab)に書かれている Q&A がわかりやすいです。 「ApplicationService からではなく、Entity から Repository を利用して、DBからの取得や更新などの操作をしても良いものでしょうか?」という質問に対する答えが下記です。
entityが複数の責務を持つことになるので、オススメしません。一般的に責務が増える、ということは凝集度が下がり、可読性やメンテナンス性を下げます。
リポジトリをアプリケーションサービスから利用しなければならないというよりは、エンティティが複数の責務を持たないほうがいいというアドバイスのように読めますが、アプリケーションサービスから利用しておけばまず大丈夫だろうと捉えました。
なお、ボトムアップドメイン駆動設計ではドメインサービスからもリポジトリを利用(*12)していて、メモアプリでも真似しました(それが良いのかどうか自分では判断できていません)。
Dart におけるインタフェース
過去には Dart にもキーワードとして interface があったようです(*13)が、今はありません。
代わりに「暗黙的インタフェース」(Implicit interface)があり、クラスを作ればインタフェースとしても機能するという便利なものです。
もう一つの代替が「抽象クラス」(Abstract class)です。 メモアプリではこちらを使いました。
カテゴリ集約のリポジトリの抽象クラスは下記のようになっています。
abstract class CategoryRepositoryBase { Future<T> transaction<T>(Future<T> Function() f); Future<Category> find(CategoryId id); Future<Category> findByName(CategoryName name); Future<List<Category>> findAll(); Future<void> save(Category category); Future<void> remove(Category category); }
なお、Dart ではメソッドのオーバーロードができないので名前で区別しています。 用途の違いが名前でわかるので、それはそれで良いなと思います。
インタフェース名
言語や開発チーム等によってインタフェースに接頭辞 I を付けたり、実装クラスのほうに接尾辞 Impl を付けたりすることが多いですよね。
ボトムアップドメイン駆動設計ではインタフェースに I を付けていますが、メモアプリでは Base という接尾辞を付けることにしました(「~Interface」でも良いですが、少し長いなと思いました)。
好みの問題です。
実装クラスのほうに付けなかったのは、インタフェース(抽象クラス)なのを明確にすることで DI しようとしていることを伝わりやすくしたかったからです(get_it を使っていることからも明白ですが)。
class NoteAppService { final NoteRepositoryBase _repository = GetIt.instance<NoteRepositoryBase>(); ... }
しかし、命名規則はチームで取り決めておいて一貫性が保てれば良いでしょう。
実装
class CategoryRepository implements CategoryRepositoryBase { ... @override Future<T> transaction<T>(Future<T> Function() f) async { return _dbHelper.transaction<T>(() => f()); } @override Future<Category> find(CategoryId id) async { final list = await (_dbHelper.txn ?? await _dbHelper.db).rawQuery( 'SELECT * FROM categories WHERE id = ?', <String>[id.value], ); return list.isEmpty ? null : toCategory(list[0]); } ...
後ほどトランザクションのところで少し解説します。
ファクトリ(Factory)
オブジェクトの生成を担うものです。
アプリケーションサービスでカテゴリやメモのオブジェクトを生成するのに使っています。
Dart には factory というキーワードがあって紛らわしいですが、別物です。

これを用意する理由が少し掴みにくいところですが、「現場で役立つシステム設計の原則」の 増田さんのブログ記事 がわかりやすいです。
エンジンが完成した後は、エンジンの責務は、シャフトを回転させること。
このエンジンオブジェクトが、組立の知識を持っているのは変でしょ? という話し。
(中略)
エンジンオブジェクトを生み出すための知識・責務は、別のオブジェクトに持たせて、エンジンオブジェクトは、シャフトを回す自分の本来の責任だけに専念すべき。
メモアプリであれば、メモを作る処理をメモ自体に持たせずにメモ工場に委譲するということです。
この他に、生成処理が分離されてテストしやすくなる効果もあります。 例えば ID を DB で自動採番するアプリであっても、テストでは DB を使わない採番方法に差し替えやすくなります。
そのためファクトリもリポジトリのように、ドメイン層にインタフェース(抽象クラス)、インフラ層に実装を置いています(が、メモアプリでは環境に依存しない Uuid() を採番に使っていてテストでも使い回せるので、テスト専用の実装はしていません)。
抽象クラス
abstract class CategoryFactoryBase { Category create({@required String name}); }
実装
class CategoryFactory implements CategoryFactoryBase { @override Category create({@required String name}) { return Category( id: CategoryId(Uuid().v4()), name: CategoryName(name), ); } }
アプリケーションサービス(Application service)
ようやくドメイン層の話が終わり、アプリケーション層(ユースケース層)に移ります。

ユースケース図に書いた「ユーザとアプリケーションの相互作用」を実装して業務の問題を解決する(ユースケースを満たす)部分がアプリケーションサービスだと思います。
基本的にドメイン層に用意したものを使うだけです。 例えば下記はカテゴリを登録するメソッドで、カテゴリのエンティティを生成するファクトリ、名前の重複を確認するドメインサービスのメソッド、DB に保存するリポジトリのメソッド、といった用意済みのものを組み合わせています。
ぱっと見て、何をしているか把握しやすいのではないでしょうか。 こんなにシンプルなのに、カテゴリ名のバリデーションの機能まで備えています。
Future<void> saveCategory({@required String name}) async { final category = _factory.create(name: name); await _repository.transaction<void>(() async { if (await _service.isDuplicated(category.name)) { throw NotUniqueException('Category name: ${category.name.value}'); } else { await _repository.save(category); } }); }
なお、上記以外の部分に一部ロジックっぽいもの(消そうとしたカテゴリの有無による分岐など)もありますが、ドメイン層で行うことではないからです。
ファクトリとリポジトリは DI できるように抽象クラスの型にしておきます(ドメインサービスは直に依存して良いものなのでアプリケーションサービス内で生成)。
ファクトリは直前に生成してコンストラクタで受け取りますが、リポジトリは main.dart で生成していて受け渡しが大変なので get_it を使っています。
class CategoryAppService { final CategoryFactoryBase _factory; final _service = CategoryService(); final _repository = GetIt.instance<CategoryRepositoryBase>(); final _noteRepository = GetIt.instance<NoteRepositoryBase>(); CategoryAppService({@required CategoryFactoryBase factory}) : _factory = factory; ... }
DTO(Data Transfer Object)

アプリケーションサービス内で取得したカテゴリやメモのデータをそのままプレゼンテーション層に返すと、それらのエンティティが持つメソッドを UI 側で使えてしまいます。
プロジェクトのポリシーによりますが、この例ではドメイン領域の知識が流出しないように DTO (Data Transfer Object)を用意する方針で記述します。
とのことでしたのでそれに倣いました。 メソッドは無く、使う側で必要とされる情報だけを持たせています。
class NoteDto { final String id; final String title; final String body; final String categoryId; NoteDto(Note source) : id = source.id.value, title = source.title.value, body = source.body.value, categoryId = source.categoryId.value; }
アプリケーションサービスから返すときに、DB から取得したデータを基に DTO を作ります。
Future<NoteDto> getNote(String id) async { final targetId = NoteId(id); final target = await _repository.find(targetId); return target == null ? null : NoteDto(target); }
クラスの命名は少し悩みました。
元のオブジェクトと区別しやすい何かを名前に付けるのが良いと思いますが、XxxxDto はちょっとダサいかなと思いつつ、他に良いものが浮かばなかったのでそれにしました。
テスト

松岡さんの記事(「DDDのモデリングとは何なのか、 そしてどうコードに落とすのか」資料 / Q&A - little hands' lab)にある Q&A には、「ドメイン駆動設計で作ったアプリケーションに対して単体テストを行うとき、意図して取り組んでいることはありますか?」という質問とその答えが載っています。
基本application層で結合テストを書きます。 ドメイン層のentityなどは複雑になったら必要に応じて書くようにしています。 テストのROIを考慮して色々試した結果それが一番よかったためです。
また、ボトムアップドメイン駆動設計 でも次のように書かれています。
テストを書く単位はアプリケーションサービスのメソッドを単位としてテストを記述すると、ちょうどビジネスロジック毎のテストになってよいかと思います。
結合テストと単体テストという意見の違いはあるようです(*14)が、アプリケーション層のテストが良いという点はお二人が一致されているので、それを採り入れるのがとりあえず最善に思えます。
メモアプリでは、既存カテゴリを変更していなくても重複扱いになって保存失敗してしまっていたのを開発途中で直し、そのときに下記のテストを追加しました。 アプリケーションサービスのいくつかのメソッドを使ったテストになっています。
test('update without change should be successful', () async { final app = CategoryAppService(factory: const CategoryFactory()); await app.saveCategory(name: 'category name'); final categories = await app.getCategoryList(); bool isSuccessful = true; try { await app.updateCategory( id: categories[0].id, name: 'category name', ); } catch (_) { isSuccessful = false; } expect(isSuccessful, true); });
Flutter では Widget のテストも行えるので、UI の操作~状態変更~表示更新までテストするとより良いですが、DDD のサンプルですのでそこまでやっていません。
わかっていない点
アプリケーションサービスは集約のうちルートしか操作できないということでしたが、NoteId のような値オブジェクトをアプリケーションサービスの中で生成しています。
この矛盾がどういうことなのか不明です。
生成するだけなら OK で、メソッドを使ってはいけないということなのでしょうか…?
データベース関連処理
データベースの扱い方についてサンプルを参考になさる方のために、簡単に解説しておきます。
メモアプリでは SQLite を使っています(sqflite パッケージを使用)。
O/R マッパーを使うと設計が変わってくるかもしれませんが、本記事では取り扱いません。
DB を扱う準備
複数のリポジトリがあっても使うデータベースは同じだったりして、リポジトリごとにオープンするのは無駄です。
そこで、DB のオープン/クローズや初期化を扱うクラス(DbHelper)を作り、Widget ツリーのルートに近いところで Provider の create で生成して使い回すようにしました。
クローズも Provider がやってくれます。

リポジトリも DbHelper と同じタイミングで生成しますが、クローズ/破棄のような後始末が不要なので get_it でインジェクトしています。
*15
Provider<DbHelper>( lazy: false, create: (_) { // DbHelper を生成 final helper = DbHelper(); // DbHelper を渡してリポジトリを生成 final getIt = GetIt.instance; getIt.registerSingleton<CategoryRepositoryBase>( CategoryRepository(dbHelper: helper), ); getIt.registerSingleton<NoteRepositoryBase>( NoteRepository(dbHelper: helper), ); return helper; }, // この Provider がツリーから除去されたときに DB クローズ dispose: (_, helper) => helper.close(), child: const CategoryListPage(), )
DbHelper の close() では DB がオープンしていないことも考慮して _db?.close() としています。
また、_db が null かどうかでオープンするか判断しているので、クローズした時には null に戻しておきます。
class DbHelper { Database _db; // この Getter にアクセスしたときにクローズ状態ならオープンする Future<Database> get db async { if (_db != null) { return _db; } ... // オープンしていないときだけここに到達 _db = await openDatabase( ... ); return _db; } Future<void> close() async { await _db?.close(); // null に戻すことでオープンしていないことを示す _db = null; } ... }
永続化データの復元
DB からデータを取り出して Category や Note のエンティティに戻す処理をエンティティ自体に書きそうになりましたが、DB のカラム構造に依存するメソッドを持たせるべきではないと気づいてやめました。
代わりに、次のようにカラムの値を取り出してエンティティに変えるメソッドをリポジトリのほうに書き、find() 等の取得メソッドでデータを返却するときにそれを使ってエンティティとして復元しています。
Category toCategory(Map<String, dynamic> data) { final String id = data['id'].toString(); final String name = data['name'].toString(); return Category( id: CategoryId(id), name: CategoryName(name), ); } ... Future<Category> find(CategoryId id) async { final list = await (_dbHelper.txn ?? await _dbHelper.db).rawQuery( 'SELECT * FROM categories WHERE id = ?', <String>[id.value], ); return list.isEmpty ? null : toCategory(list[0]); }
リポジトリの中で CategoryId 等エンティティを使っている(ドメインオブジェクトのうち集約ルートでもないものを扱っている)ことが不安ですが、ボトムアップドメイン駆動設計でもそうなっているので良しとしました。
トランザクション
一連のDB操作の途中で失敗したときや、複数のユーザが同時に操作したときなどのために、トランザクションは必須です。
ボトムアップドメイン駆動設計 では、テーブルのカラムに UNIQUE にすれば重複登録を失敗させることができるもののソースコード上でそのことがわかりにくいという問題点があり、別の方法が必要だけれど言語によっては一工夫必要になる旨が説明されています。
- C# では
トランザクションスコープというものでトランザクションの範囲を明示する - 言語によってはアノテーション等でトランザクションを示す
- そのような機能がない言語では
ユニットオブワークを使う(*16)
Dart にはトランザクションスコープはありませんが、Flutter で使える sqflite では
db.transaction((txn) async { // この中で txn を使って一つのトランザクションとして扱える });
のようにしてトランザクションを扱えるようになっていて、少し苦労しましたがトランザクションスコープに近い書き方ができました。
下のコードのように DbHelper に db.transaction() を利用するメソッドを用意し、リポジトリからそれを呼び出せるようにします(アプリケーションサービスは DbHelper に依存してはいけないためリポジトリ経由で使います)。
class DbHelper { Database _db; Transaction _txn; Transaction get txn => _txn; Future<T> transaction<T>(Future<T> Function() f) async { return db.then((db) async { return db.transaction<T>((txn) async { // トランザクションのインスタンスを開始時にフィールドに持たせる _txn = txn; return f(); }).then((v) { // 終了時に null に戻す(= トランザクション中でないことを示す) _txn = null; return v; }); }); } }
class CategoryRepository implements CategoryRepositoryBase { ... // アプリケーション層からは DbHelper のメソッドを直接使わずにこれを経由する @override Future<T> transaction<T>(Future<T> Function() f) async { return _dbHelper.transaction<T>(() => f()); } ... }
トランザクションが始まったときに DbHelper のフィールド(_txn)にそのトランザクションのインスタンスを入れ、終わったら null にしています。
リポジトリでは _txn に値があればその値(トランザクションのインスタンス)、null ならデータベースのインスタンスを使ってデータベースの操作を行います。
下記の (_dbHelper.txn ?? await _dbHelper.db) という部分がそれです。
※2020/3/14 更新
txn と db の使い分けを DbHelper で行うようにし、db(getter)を _open() というライブラリプライベートなメソッドに変えました。
*17
最新のコードは リポジトリ をご覧ください。
class CategoryRepository implements CategoryRepositoryBase { ... @override Future<Category> find(CategoryId id) async { // トランザクション中かどうかでインスタンスを使い分ける final list = await (_dbHelper.txn ?? await _dbHelper.db).rawQuery( 'SELECT * FROM categories WHERE id = ?', <String>[id.value], ); return list.isEmpty ? null : toCategory(list[0]); } ...
アプリケーションサービスではトランザクションが必要な部分を _repository.transaction<戻り値の型>(() async { トランザクションが必要な処理 }) のように囲うだけです。
class CategoryAppService { ... Future<void> saveCategory({@required String name}) async { final category = _factory.create(name: name); // 一つのトランザクションにしたい部分を囲む await _repository.transaction<void>(() async { if (await _service.isDuplicated(category.name)) { throw NotUniqueException('Category name: ${category.name.value}'); } else { await _repository.save(category); } }); } ...
DbHelper の _txn に入っている値によってトランザクションかどうかが変わるので、並行的な DB 処理がある場合には使えませんが、逐次であればこれで足りるかと思います。 *18
なお、sqflite のトランザクションではロールバックは意図的にできず、db.transaction((txn) async { ... }) の中で処理が失敗したときに勝手にロールバックされるようです。
コミットも自動です。
プレゼンテーション層
残りわずかです。
Notifier

導入編 で書いたとおり、ChangeNotifier を継承したクラスをモデルと呼ぶことにして presentation/model/ というパスに置いています。
クラス名も XxxxModel としています。
XxxxNotifier にしてフォルダ名も「notifier」で良かったんじゃないかと今思いますが、簡単に変えられるところなのでご自身の好みで変えていただければと思います。
ChangeNotifier を Mixin したクラスであって「notifier」のほうがわかりやすいので後で変えました(上のスクショは元のままです)。
ここの役割は下の層への入口や橋渡しのようなものであり、かつ、状態を持っていてその変更が通知されて Widget のリビルドが走るというものです。
ではコードを見てみましょう。
class CategoryNotifier with ChangeNotifier { final CategoryAppService _app; CategoryNotifier({@required CategoryAppService app}) : _app = app { _updateList(); } List<CategoryDto> _list; // 変更不可にしたリストを渡す List<CategoryDto> get list => _list == null ? null : List.unmodifiable(_list); Future<void> saveCategory({ @required String name, }) async { await _app.saveCategory(name: name); _updateList(); } Future<void> updateCategory({ @required String id, @required String name, }) async { await _app.updateCategory(id: id, name: name); _updateList(); } Future<void> removeCategory(String id) async { await _app.removeCategory(id); _updateList(); } void _updateList() { _app.getCategoryList().then((list) { _list = list; notifyListeners(); }); } }
このように、ほぼアプリケーションサービスのメソッドを使うだけです。
UI 層での操作をきっかけに、このモデルを通してアプリケーション層、ドメイン層のメソッドが呼び出されていってドメインオブジェクトの処理によって状態が変わり、その変更を notifyListeners() で通知しています。
少し気を配ったのは次の部分です。
List<CategoryDto> get list => _list == null ? null : List.unmodifiable(_list);
DTO はデータ返却専用のオブジェクトであり、中身は final なので変更できないのですが、返されたリストを受け取った側で要素を差し替えることはできてしまいます。
それを不可能にするために List.unmodifiable() を使いました。
*19
*20
DDD に取り組み始めてからそういった安全意識が高まってきた実感があります。 このように設計全般に対して考え方を改善できるという意味でも DDD を学ぶのは有益だと思います。
他の部分
プレゼンテーション層の他の部分については DDD 関連で特筆するところはありません。 下の層をしっかりと作っておくことで、いつの間にかちゃんと機能するものが出来上がっていたという印象です。
例えば、バリデーションやそのエラー(例外)の処理をドメイン層で先に済ませているので、カテゴリ名等を編集するダイアログでは例外時にエラー表示するように書くだけです。 下ごしらえがしっかりとできている3分クッキングのようです。 機能を変えるときにもおそらく下ごしらえのほうを局所的に変更すれば済むと思います。
アプリ開発の途中に混乱してしまうことが多い人は、ぜひ DDD を取り入れてみてください。
改善の余地
コレクションオブジェクト(ファーストクラスコレクション)
ドメイン層でコレクション(List や Map)を扱う必要がある場合、それをオブジェクトにすると、例えば List 内の値を合計するといった処理をメソッドとして提供できて扱いやすくなります。
メモアプリでは作る必要がなかったのですが、他のアプリを使うときにコレクションオブジェクトを作ると助かる場合があることを覚えておくと良いと思います。
export
ファイルのエクスポートをしているところが多数あります。
例えば domain/note/note.dart は下記のようになっています。
そうしておけば、note.dart をインポートしたファイルで note_body.dart 等のインポートを省いても NoteBody 等を使うことできて楽です。
import 'package:meta/meta.dart' show required; import 'package:flutter_ddd/domain/category/value/category_id.dart'; import 'package:flutter_ddd/domain/note/value/note_body.dart'; import 'package:flutter_ddd/domain/note/value/note_id.dart'; import 'package:flutter_ddd/domain/note/value/note_title.dart'; export 'package:flutter_ddd/domain/category/value/category_id.dart'; export 'package:flutter_ddd/domain/note/value/note_body.dart'; export 'package:flutter_ddd/domain/note/value/note_id.dart'; export 'package:flutter_ddd/domain/note/value/note_title.dart';
しかし、8月末にあった DDD のイベント で「インポートの記述を見ればおかしな依存をしていないか判断できる」というような話があり、なるほどと思いました。
エクスポートしてしまうとインポートを省略して依存のミスに気づきにくくなってしまいそうです。 そう考えるとエクスポートしないほうが良いかもしれません。
やはり「実装ドメイン駆動設計」
この記事を書きながら、曖昧にしか理解できていないところがまだ多いと気づきました。 調べていくと実践ドメイン駆動設計の本から引用された情報に辿り着くことが多く、やはりその本を読むのが近道だろうなと感じました。 高価なものですが、他の人の評価も高くて価値があるようです。
おわり!
長文をお読みいただきありがとうございました。
間違いなどありましたらどうぞお知らせくださいませ。
*1:必ずしも一ヶ所で済ませるのが良いわけではないようです。ドメイン層と UI 層の両方で行うのは悪くないという話が DDD Radio 第2回公開収録 というイベント内で出ていました(音声はそのうち こちら に上がると思います)。ドメイン層は防御、UI 層は UX のためという目的の違いがあるとのことです。確かにそうですね。
*2:ボトムアップドメイン駆動設計 より引用。
*3:@immutable のアノテーションを使うには package:meta/meta.dart のインポートが必要です。
*4:この比較において、渡されたオブジェクトが null でないことも確認しようと思いましたが、analysis_options.yaml で avoid_null_checks_in_equality_operators を有効にしていると「Don't check for null in custom == operators.」の警告が出るのでやめました。
*5:詳しくは ボトムアップドメイン駆動設計 をお読みください。
*6:ボトムアップドメイン駆動設計 より引用。
*7:ボトムアップドメイン駆動設計では User エンティティの ChangeUserName() 等でもバリデートされていますが、二重に検証することになるのでメモアプリでは避けました。
*8:Dart ではアクセス許可したい範囲を同一ライブラリにすれば library private となって可能ですが、part の記述が手間です。また、そのような構造にした理由が伝わるように管理しておく煩わしさも出てくると思います。
*9:これらの箇条書きだけでは伝えきれませんので、ボトムアップドメイン駆動設計 や GitHub のプロジェクト をご覧ください。
*10:AggregateRoot - 集約 │ nrslib がわかりやすいです。
*11:ボトムアップドメイン駆動設計 より引用。
*12:https://github.com/nrslib/BottomUpDDDTheLaterPart/blob/c8d6c081041030f2ad2584750c971857686b3bf6/src/Domain/Domain/Users/UserService.cs#L11
*13:class - Was the "interface" keyword removed from Dart? - Stack Overflow
*14:ドメイン層の複数のメソッドを組み合わせて作られているアプリケーションサービスのメソッドを単体テストするのは結合テストとも言えるでしょうか…。
*15:provider v4.0.0 で create に渡した処理の実行が lazy になり、get_it で渡したものを使いたいタイミングよりそのインスタンスの生成が後になってしまいます。対策として lazy を false にしています。
*16:ボトムアップドメイン駆動設計 では「業務のトランザクションを作業の単位として保持するための仕組みです。」、P of EAA: Unit of Work というページでは「Maintains a list of objects affected by a business transaction and coordinates the writing out of changes and the resolution of concurrency problems.」(ビジネストランザクションの影響を受けるオブジェクトのリストを保持し、変更内容の書き込みや並行性の問題解決を取り計らう)とされています。
*17:このアプリではサンプルとして簡潔にするために、初期化済みかどうかを使用時に確認するようにしています。実際には、パブリックなメソッドにしてアプリ起動時の一連の初期化処理内で呼ぶのが良いと思います。
*18:並行処理にしたい場合は、常にトランザクションを使うようにすれば良いかもしれません。
*19:残念ながら Lint のチェックでは引っかからないようです。
*20:List.unmodifiable() では要素の差し替えを防ぐことはできますが、要素として持つオブジェクトの final でない field が変更されるのを防ぐことはできません。DTO は immutable なので安全ですが、そうでないものに対して使う場合にはご注意ください。
Dart/Flutterでドメイン駆動設計(DDD)してみた - 導入編
カテゴリ別にメモを管理できるアプリの開発を DDD(Domain-driven design)でやってみたものです。
二つの記事から成り、この記事はその一つ目です。
- 導入編(本記事)
解決しようとした問題点や、DDD と関連用語の意味の他、モデリング・レイヤ分け・ディレクトリ構成の検討において考えたことなどをまとめています。 - 実装編
Dart/Flutter での実装を中心としますが、一つ目で触れていない点(集約など)の説明も含みます。
やってみようと思った経緯
何かを作るとき、設計がメチャクチャであっても運良くそれっぽく出来上がることがあります。 小さなものなら直しやすかったり、あるいは問題があまり顕在化しなかったりするかもしれません。
しかし、大きなものでは次第に破綻してしまうことが容易に想像できます。
Flutter でも、小さなアプリを作って学ぶ間は「なんて簡単にできるんだ!」と感動したものですが、その段階を過ぎて大きめのアプリを作り始めたとき、急に悩むようになりました。
出てきた問題点
- ビジネスロジックのクラスが肥大化した
- API・DBの操作処理などのファイルを分けたら依存関係が混沌とした
- どこに何の処理が書かれているか見えにくく、似た処理が複数箇所に散らばって無駄が生じた
- そうなったことに気づいていたが、改善が難しかった
- 何日間か中断してから再開すると構成を忘れていて読み解かないといけなくなった
- ちょっとした変更の影響が大きくなって手間取った
ビジネスロジックを UI から分離するのは既にやっていてもそうなってしまい、何か別の解決策があるはずだと考えて模索した結果「これだ!」と思えたのが DDD です。
主流のアーキテクチャパターンではダメ?
ネイティブアプリ開発では MVP、MVVM といったものが主流のようです。 アプリ側の経験は少ないですが、MVVM は BLoC パターンと共通しているものがあると思えて調べてみました。
flutter - MVVM vs Bloc patterns - Stack Overflow
これによると、両者はほぼ同様の考え方だと捉えて良いようです。
その二つが似ているのであれば、BLoC パターンで解決できない問題は MVVM でも同じなのでは…。 それよりも DDD を取り入れるほうが確実に解決できるはずだと考えました。
何が変わるか
ChangeNotifierProvider を用いていて、これ自体は変わったことではありません。 状態管理やリビルドの制御の方法として一般的になってきているものです。 それを使ったよくあるサンプルとの違いは、Model をより細かく設計(DDD)しているという点です。
また、「メモのタイトル専用の型(使うときに文字数のバリデーションも同時に行う)」「タイトルの変更(タイトルを作り直してエンティティが持つ値を差し替える)」といった機能を細かく作って組み合わせ、アプリケーションサービスで取りまとめておくことで、Flutter の UI 側からそれらの機能を使うときに「あれ?もうほとんどできてる!」という驚きを感じるくらい自然に出来上がっていきました。
主に参考にしたもの
DDDって何?と思っていたときに最初に読み、取り入れていこうと思うきっかけになった本です。 増田さんによる本ですので、以後は短く「増田本」と呼ばせていただきます。
ボトムアップデザイン駆動設計
ボトムアップデザイン駆動設計 後編
増田本を読んで良さがわかったものの具体的な実装がわからないというモヤモヤがこの記事で解消されました。 スライドもわかりやすいので、そちらをさっと見てから記事を読むと良いかもしれません。 コードは C# ですが、Dart な人にも理解は難しくないと思います。
調べていると辿り着くことが多く、疑問が解けるような明解な情報が多いです。
また、今回のコードをほぼ書いてから、答え合わせのように 2019-08-31 の記事 を読みました。
同じ方(松岡さん)が Twitter に時々書かれている質問箱の回答もとてもわかりやすいです。
「体験 ドメイン駆動設計」という貴重な特集があり、作った後に読んで復習になりました。
読み終えていないもの
購入して少しだけ見たところから進んでいません。 評判を聞く限り、どちらも大変為になる良書ですが、いきなり読むと難しいかもしれません。
実践ドメイン駆動設計
「エリック・エヴァンスのドメイン駆動設計」よりもこちらから入ったほうがわかりやすいそうです。
Clean Architecture 達人に学ぶソフトウェアの構造と設計
はじめにご理解ください
- DDD について学びながら作ったサンプルです。奥が深い DDD を部分的に理解した段階で作ったものですので、間違った捉え方をしている部分があるかもしれません。
- 上記の「ボトムアップデザイン駆動設計」をベースにしましたので、DDD の本質的なところはそちらをお読みください。
- その記事では「ユーザ」と「サークル」が出てきますが、私のサンプルでは「メモ」と「カテゴリ」にしています。
- Flutter に依存するのは UI(プレゼンテーション)層とインフラストラクチャ層のみで、この記事の中心部分は Dart と DDD の話になります。
用語(ドメインやモデルとは)
DDD で使われる用語には DDD 以外でも聞いたことがあるものがあります。 MVC の M もモデルであり、データベースに関連することを行う部分というイメージです(この捉え方自体が間違っているようですが)。
そのような既知の言葉のイメージが理解の邪魔になりました。 同じ呼び名であっても DDD の文脈では別の意味だったりします(「エンティティ」など)。 もともと知っている言葉に引きずられないようご注意ください。
ドメイン(Domain)
松岡さんの ドメイン駆動設計は何を解決しようとしているのか より:
業務アプリケーションに限って言うなれば、「アプリケーションの対象となる業務領域」とでも言うとわかりやすいでしょうか。
ドメインモデル(Domain model)
WEB+DB PRESS の特集記事より:
業務範囲の様々なことを抽象的に表す模型のようなものが「モデル」、その模型を抽出する作業が「モデリング」だと私は捉えました。
ドメインオブジェクト(Domain object)
「ドメインモデル」の他に「ドメインオブジェクト」という言葉もよく目にします。 同じ意味で使われることも多いようですが、おそらく本来は、前者が先述のとおりの模型のようなもの、後者がその模型を実際のオブジェクト(クラス)として実装したものだろうと思います。
ドメインモデル貧血症(Anemic domain model)
増田本を読んでいると、「判断/加工/計算」といった処理をドメインオブジェクトに持たせることが何度も説かれていて、DDD の中でとても大事な考え方の部分なのだと伝わってきます。
ある部品が行うべき処理をその部品側でなくそれを使う側に書くと、同じ目的のコードが複数の箇所に重複して散在しやすくなります。 データを格納するだけのデータクラスを作るのではなく、そこにロジックも一緒に持たせることでそれを防ぐことができ、変更が容易なシステムになります。
ここで WEB+DB PRESS Vol.113 の特集記事の第5章にある一文をご紹介します。
すべてのコードが「あるべきところにある」というだけで、どれほどの開発者が幸福でいられるでしょうか。
何だかとても印象深い言葉で、まるで DDD のキャッチコピーのような名言です。
これに反するのが、ドメインオブジェクトにドメイン知識が欠乏している「ドメインモデル貧血症」と呼ばれる状態です。 名前が付くほどのアンチパターンですので、そうならないよう肝に銘じておきましょう。
利口な UI(Smart UI)
ユーザインタフェースがビジネスロジックを持ちすぎてしまっているアンチパターンであり、ドメインモデル貧血症の原因になるものです。 UI とロジックの分離ができていないという DDD 以前の状態ですね。
Flutter でもそういう書き方ができてしまいます。 後で分けようと思って一時的にでも書いてしまうと悪化していくので、最初から注意したいところです。
ドメイン駆動設計(Domain-driven design)
「なるほど」と思える説明がまたまた WEB+DB PRESS Vol.113 の特集記事にありましたので引用しておきます。 その特集には他にも多数の重要な情報が詰まっていますが、ここに全て抜粋するわけにはいきません。 購入して特集全体を読まれることをお勧めします。
実を言うとDDDが求めることはとても単純です。ドメインに焦点を当て、対象を正しく理解し、表現すること。
(中略)
言ってしまえば当たり前のことを当たり前にやるためのプラクティスがDDDです。
「当たり前のことを当たり前にやる」、これも名言ですね。刺さりました。 本来は当たり前のことができていれば悩む必要がないのでしょう。 まず何が当たり前なのかわかっていなかったのかもしれません。
DDDはドメインと向き合い、分析から設計、そして開発が相互に影響し合うよう努力を重ねることでイテレーティブな成長を促す手法です。
単にコードの見通しを良くするような目的で取り入れるものではなく、プロダクトやビジネス自体にとって成長に繋がる手法だと捉えるのがいいですね。
DDDの目標はプロダクトの関係者が一丸となり、共通の認識を持って知識を深め、プロダクトを改良し続けることです。
ビジネスサイド・開発サイドと二分した考えでいると実現しにくいことだろうと思います。 「ビジネスには興味がない、技術が第一だ」と考えていると成し得ないわけです(耳が痛い…)。 開発者にとっては意識の転換が必要になりますね。
これらの引用の他、もう少し後に載せている松岡さんの「モデリングから利益を得るためのアプローチ」の図や引用元の記事もわかりやすいです。
コードの面では、オブジェクト指向の役割が大きいなと感じます。 そこの理解が浅いとご自分で思われる方は、まずそこを強化されると良いかと思います。
戦略的/戦術的設計、軽量 DDD
ドメイン駆動設計のメリットと始め方 ~ 1章「DDDへの誘い」 (1/3):CodeZine(コードジン)
こちらに書かれているのがわかりやすかったです。
戦略的設計(Strategic design patterns)
「チームで使うパターン」のことです。ビジネスにおける言語に価値を置き、業務に関わる人の考え方をドメインモデルとして表現します。
戦術的設計(Tactical design patterns)
「テクニカルなパターン」のことです。アーキテクチャ、DDD固有のパターンといった技術的な内容が含まれます。
軽量 DDD(DDD-Lite)
なお、「戦略的設計」を実施せず、エンジニアが取り組みやすい「戦術的設計」にだけ注力すると、「軽量DDD」と呼ばれる事業価値を発揮できない貧弱なDDDになってしまうため注意が必要です。
DDD を形だけ取り入れるのは不十分なんですね。 軽量 DDD から入ることを勧めている人が時々いますが、上記を理解すると危険だなと思います(が、取り組みやすくてある程度の改善も見込めるので絶対悪ではないのかもしれません…)。
ドメインモデリング
履歴書をモデリングするというちょっとした例が特集記事に書かれていてわかりやすかったのですが、「名前」「経歴」等のあらゆるものをモデルとして抽象化するのは無理があるし、「資格」の情報が抜けていれば採用の判断に不十分なものになってしまうということで、必要十分なものを取捨選択するのがモデリングでは大事なんだなと思いました。
他に、松岡さんの記事(ドメイン駆動設計は何を解決しようとしているのか)の「日報のモデリング」の例もわかりやすいです。
モデリングの意味
モデリングや DDD そのものの意味も 同じ記事 で解説されていて、そこに書かれているように「意図を組んだ上で取り組むことができるようになる」と思います。ぜひお読みください。
ここにはその記事からお借りした図を貼っておきます。

ユースケース図
ドメインモデリングのためには、まず「ユースケース図」を描いてモデリングの範囲を絞るのが良いようです。

ボトムアップドメイン駆動設計 のこの図とほぼ同じになるので脳内でしか描きませんでしたが、後で真似て描いてみました(PlantUML を使いました)。

こんな図で良いのでしょうか…。
そもそも「ユースケース」とは何なのか悩んだのですが、WEB+DB PRESS の特集記事によれば「ユーザーとアプリケーションが行える相互作用の種類」とのことでした。 上の図ではユーザが行うことばかりになっていますが、「相互」なのでユーザに向かう矢印もあり得るのかもしれません。
話を戻すと、このようにユーザとアプリの間で行われることを図にして、重要な部分を特にモデリングするように範囲を絞るために見るのがユースケース図だと思われます。
メモアプリのサンプルでは特に対象外にする部分はなさそうですが、もし「メモをバックアップする」という機能があれば、最初から含めるのはやめて一旦モデリングの対象外にするかもしれません。
ドメインモデル図
ドメインモデル図を描くことがモデリングの本格的な過程の部分だと思います。
ですが、ボトムアップドメイン駆動設計にはドメインモデル図は出てきませんでしたので、サンプル作成時にはスキップしました。 次の図は後で描いてみたものです。

松岡さん流の簡易的なクラス図のようなダイアグラムです。 「現場でDDD!のハンズオン、持ち帰ってやってみた」で次のように説明されています。
これに倣ってルールを吹き出しに書いていますが、メモのほうの「存在しないカテゴリIDを指定できない」は実装していません。 図を後で描いたときに抜けていることに気づいたものです。 やはり先にこのような図にしたほうがいいなと実感できました。
さて、上の図では集約が二つあり、その中にオブジェクトが一つずつあります。 各集約にエンティティが一つと値オブジャクトがいくつかあるだけ(一つずつのエンティティがそのまま集約ルート)なので、シンプルすぎる図になりました(集約等の詳細は後述します)。
もっと複雑なアプリであれば、概念や用語が適切でなかったり含め忘れているオブジェクトやルールがあったりする可能性があり、このモデリングの過程で気づいて改善していくことが重要になるはずです。 また、集約の境界もそこで決めることになります。
※ボトムアップドメイン駆動設計ではサークルのエンティティにユーザ(のID)のリストを持たせていますが、メモアプリではメモにカテゴリIDを持たせました。 リストを持たせるならドメインモデル図は変わってきます。そういった検討もこの段階でできると思います。
ディレクトリ構成
構成を考える上でアーキテクチャが関係してくるので、まずそれを見ていきます。
増田本では、業務アプリケーションは 三層アーキテクチャ が一般的だとしています。
また、三層+ドメインモデル にして、ドメインモデルに集めたロジックを三層が利用することが勧められています。
しかし、アーキテクチャには様々なものがあります。
複数のアーキテクチャ
ドメイン駆動設計で実装を始めるのに一番とっつきやすいアーキテクチャは何か[DDD]
またまた松岡さんの記事です。情報が豊富でありがたいですね。
各アーキテクチャの図をどう見ればいいのか最初はわからなかったのですが、どのアーキテクチャにも層があり、層が依存する方向が図で示されているのだと理解しました。
上記四つのうちでは オニオンアーキテクチャ が松岡さんオススメのものです。
上下に重ねた図になっていて、丸い玉ねぎ状よりわかりやすいです。

書かれているとおり「上の層から下の層」という依存方向なので、アプリケーション層に書かれたものをドメインモデルが使うのはダメだけれど逆は OK ということがわかります。
依存関係逆転の原則(DIP)
SOLID 原則の一つで、これがとても大事だそうです。
先ほどの図でもこの原則が踏まえられているようですが、より明確になるよう改良された図が松岡さんの別の記事(新卒にも伝わるドメイン駆動設計のアーキテクチャ説明[DDD])にありました。下図が転載したものです。

インフラストラクチャ層はデータの永続化などを行う層で、レイヤードアーキテクチャでは最下層に来るものです。 その位置を逆転して上に持っていった図になります。
永続化にはデータベースなどの外部のツールが必要になりますが、その処理を担当するインフラストラクチャ層が下にあればドメイン層がそこに依存してしまうことになります。 そうすると、プラットフォームへの依存も起こってきます。
DDD ではドメインを他に依存させない考えがあるのでドメインが最下層になることが重要であり、そのために永続化処理のインタフェースだけを下層(ドメイン層)、実装を上層(インフラストラクチャ層)に置くことになります。 実装は差し替えることができるので、テストにおいても大きな意味を成します。
これはオブジェクト指向だからこそ実現できるものですね。 理解したときは少し感動しました。
アーキテクチャについてもう少しだけ…
先ほどの図で変更された点について次のように書かれています。
- ApplicationServiceという呼称をUseCaseに変更した
- Infra層からDomain層への依存を実装の矢印で表現した
- Domain層をModelとServiceに分けるのはやめて一つにした
- 登場要素をマッピングした
アプリケーション層 が ユースケース層 という呼称に変わっています。
「ユースケース」と言えば「ユースケース図」を先ほど描きましたね。
あのユースケース図に載せた処理を扱う層だと言えそうです。
また、「ModelとServiceに分けるのはやめて一つに」ということで、結局「三層+ドメインモデル」に近い四つの層になっています。 増田本ではインフラストラクチャ層ではなくデータソース層となっていますが、これもほぼ同じものだと思います。
ようやくディレクトリ構成
というわけで、今見た層をディレクトリ分けに使えば良さそうです。
その前に、ボトムアップドメイン駆動設計のスライド にある構成例を参考に見てみましょう。

この中で次の二点が少し気になりました。
- Application が Domain の下にある
- Domain の下に Model があるが、GitHub の実際のコード を見ると Model ではなく Domain であり、Domain の下にまた Domain という構成になっている
この二点について自分でアレンジし、presentation、application、domain、infrastructure の四つが lib の中で並列になるようにしました。

他にも考慮した点がありますので書いておきます。
- application
「ボトムアップドメイン駆動設計」の記事をベースにしたので「application」にしました。 先ほどの図のように「usecase」という名前にするのも良いと思います。 「service」はドメインサービスと紛らわしいので避けました(ドメインサービスについては 実装編 を参照ください)。 - application/dto
ボトムアップドメイン駆動設計のコードには Application の下に Models があって DTO のファイルが入っています。 それを model と呼ぶのはどうかと思い、そのまま「dto」としました。 - presentation/notifier
MVVM に照らすと ViewModel に該当するので、それを短く表して「model」としました(プレゼンテーション層なのでドメインモデルと混同することはないでしょう)。
わかりやすく「notifier」に変更しました。 ディレクトリ名もクラス名も変えています。 - test
ボトムアップドメイン駆動設計の構成例には永続化処理のテストのための InMemory がありますが、Flutter にはテスト用ディレクトリが用意されているのでそれを使います。 - common
依存を無視して共通処理のディレクトリを作っていいのか迷いましたが、Exception のクラスはアプリケーション層からもドメイン層からも使うので作りました。 - lib/src
Dart には lib の下に src というディレクトリを作る(他のライブラリから読み込まない private なコードをそこに置く)という慣習がありますが、パッケージではなく一つのアプリを作るときには必要性を感じないので lib 直下に配置しました。 なお、Flutter チームのサンプルアプリでも必ずしも src があるわけではありません。 - 単数形
dto、pageなどはその中に複数の DTO や複数ページ用のファイルがあるので複数形にしたかったのですが、dtos という複数形は読みにくいのでやめました。
パッケージ?
先ほどの「ボトムアップドメイン駆動設計」のディレクトリ構成例ではパッケージやフォルダが色分けされています。 その記事のコードは C# なのでパッケージ(namespace)として分割されています。
これを Dart/Flutter ではどう扱えば良いでしょうか…。
「パッケージ」は Dart にもありますが、C# の namespace とは異なるものです。
他に「ライブラリ」という概念もあります。
基本的には一つのファイルが一つのライブラリですが、library、part、part of というキーワードを使って複数のファイルに分けることもできるので、これを namespace のような括りに使えそうです。
ただ、問題が二点あると思いました。
- 分割したファイル分の
partの記述が必要
ライブラリの中にファイルが増えるたびに追記していかないといけなくて手間です。 - キーワードの可視範囲が広くなりすぎる
Dart ではメソッド等の名前をアンダースコアで始めると不可視になりますが、これは library private(クラスの外から見えないのではなく他のライブラリから見えない)です。 一つの層を一つのライブラリにしてしまうと、アンダースコアを付けたものが同じ層のどこからも見えてしまうことになります。
そこで、単にディレクトリとして分けるだけにしました。
疑問、懸念
何がどこにあるという取り決めをしておくことでわかりやすくなり、それでメリットがあるのだから OK と受け取っておけば良いのでしょうか…。 実装をドメイン層に置いたり上の層に依存しようとしたりするとエラーになる、といった言語や IDE による制約や支援がないと、開発チーム内で共通認識しておくルールでしかなくなってしまい、人為的に誤った記述をしてしまうのを防げないように思えます。
パッケージに分けて、どのパッケージからは見えるという指定まで可能な言語だとやりやすそうです(Scala のアクセス限定子は可能?)。 Dart の言語自体には残念ながらそういう機能はありませんが、package:meta が提供するアノテーションの中に役立つものがあるかもしれません。
Flutter + DDD で何が変わるのか
ChangeNotifier を使うパターンの場合、よくある形をシンプルに描くと次のような図になると思います。 BLoC パターンでも ChangeNotifier の部分が BLoC に置き換わる感じです。

ChangeNotifier や BLoC の部分にビジネスロジックが来ますが、そこの設計は自由で、あまり考えずに書くと少数の巨大なクラスにしてしまうこともあり得ます。
一方 DDD &オニオンアーキテクチャを採用すると、次のように細かく設計することになります(矢印は依存の方向)。 この場合、ChangeNotifier や BLoC は、UI から Application 以下の層への入り口のようなものになると考えています。

クラスの数が多くなって(一見)複雑になったり、設計にコストがかかったりするので、アプリの規模、開発メンバー数/スキル、予算等によって検討したほうがいいですね。 後で改修が難しくなって余計にコストがかかることや、不具合の修正が困難になって困ることを考えると、そうなりにくい DDD のほうがメリットが大きいように個人的には思います。
注意
ボトムアップドメイン駆動設計 に次のように書かれています。
ボトムアップドメイン駆動設計で実践してきたドメイン駆動設計は形を踏襲しただけの紛い物です。
原典では個々のパターンの繋がりが想像しづらいので、それらの繋がりがわかるように動くものを用意したに過ぎません。ドメイン駆動設計のマインドは原典を読んで感じ取ってください。
後編の最後に書かれている部分です。 ここまでしっかりと読まないまま参考にしていて、後で読んで「え、そうなの…?」と思いましたが、DDD の意味などの理解が深まってくると確かにそうだなと感じます。
上の図で表しているのも形だけであり、その形だけに捕らわれると「軽量 DDD」になってしまいますね。 単に「この形に似せて作るものなのだ」と受け取るのではなく、ドメインをよく理解して何のためにどうしたいのかを考えて設計しましょう。
実装編に続きます…
一つの記事にしようと思いましたが、合わせると一冊の薄い本になりそうな分量になってしまいました。 ここで一度区切りをつけ、続きは別の記事にしようと思います。
【Dart】シンプルに派生クラスを作る(別名の代わり)
クラスに別名を付けることができれば後述の問題が解決するのですが、今のところできないため、代わりに 元のクラスと機能は同じままで継承するシンプルな方法がないか調べてまとめた記事です。
※タイトルに「複製」という言葉を使っていましたが、同じものが出来上がるわけではないので変更しました。 id:ntaoo さんありがとうございました!
悩んだ問題
Flutter で provider を使うときに少し悩むことがあります。
同じ型の値を複数渡せないという問題です。
List や Map に入れるとできるのですが、ちょっとぎこちないやり方に思えます。
List 等を使わない場合、次のようになります。
MultiProvider( providers: [ Provider<TextEditingController>( builder: (_) => TextEditingController(), // a ), Provider<TextEditingController>( builder: (_) => TextEditingController(), // b ), ], child: Hoge(), )
class Hoge extends StatelessWidget { @override Widget build(BuildContext context) { // 二つとも b のオブジェクトになってしまう final titleController = Provider.of<TextEditingController>(context); final bodyController = Provider.of<TextEditingController>(context); return ...; } }
使用箇所に最も近い TextEditingController (b のほう)しか取れません。
解決策
これは同じ型だから起こります。
それなら異なる型名を使えばいいですね。
そこで、クラスにエイリアス(別名)を付けることを考えたのですが、現時点ではできないことがわかりました。
代わりに同じ中身の別クラスを作ることなら可能です。
1) べたな方法
class TitleEditingController extends TextEditingController {}
2) 別の方法
class TitleEditingController = TextEditingController with Type;
with Type とは
もし 2 で with Type を付けて Type というものを mixin しないとエラーが出ます。
Classes can only mixin other classes.
Type の定義を見ると、中身のない抽象クラスになっています。
abstract class Type {}
形だけでも mixin しないといけないということですね。
これはこれであまり美しくない感じがしますが、仕方ないですね。
注意
先ほども書いたのですが、これはエイリアスではありません。
既成のクラスに Mixin 適用して作った新たなクラス/型です。
typedef for simple type aliases · Issue #2626 · dart-lang/sdk · GitHub
class Foo = Bar with Mixin syntax is used to create a new type. Such that Foo != Bar
元の型とは当然別物として扱われます。
名前だけ異なる同じ型だと考えて使うと失敗する場合があるので注意してください。
class Foo = Bar with Type; print(Foo == Bar); // false(同じ型ではない) Bar bar = Foo(); // OK Foo foo = bar; // OK foo = Bar(); // エラー
作ったクラスのオブジェクトを元のクラスの型として扱うこと(アップキャスト)は可能です。
そのため、TextEditingController を渡す部分に代わりに TitleEditingController を渡すことができます。
ダウンキャストについては、アップキャストしたものを本来の型にダウンキャストするのはOKですが、いきなりダウンキャストするのはエラーになります。
制限
プリミティブな型には使えない
プリミティブな型にも使えると便利なのですが、それはできないようです。
例えば、int を基にして myInt を作ろうとしてもエラーになります。
// Classes can't extend 'int'. というエラーが出る class myInt = int with Type;
親のコンストラクタに引数があるなら継承する方法は不向き
親クラスが引数のあるコンストラクタを持っている場合、子クラスで親のコンストラクタを呼ばないといけないため、結局シンプルにできません。
Mixin する方法では const でなくなる
親が const コンストラクタを持っていても、with Type のほうの方法で作ったクラスのコンストラクタは const になりませんでした。
今後の改善
クラスにもプリミティブな型にも typedef でエイリアスを付けられるようになりそうです。
このことは先ほどと同じ issue でコメントされています。
As of 02bb437 (Jan 11, 2019) it is part of the language specification that you can write type aliases like typedef C = D
; and typedef D = Map<X, List >;, etc. There's an implementation plan. Right now some other things are being pushed harder than this feature, but it's accepted and in the pipeline.
Note that you can not use this feature to create new types (similar to Haskell's newtype or Pascal's type Temperature = Integer;), it creates an additional notation for an existing type. So if you declare typedef D = C; then it is type correct to have things like D d = C();.
typedef for simple type aliases · Issue #2626 · dart-lang/sdk
・https://github.com/dart-lang/sdk/issues/2626#issuecomment-464307003
・https://github.com/dart-lang/sdk/issues/2626#issuecomment-464638272
続きの議論は下記 issue で行われています。
定義の例
typedef C = D<int>; typedef E<X extends num> = Map<X, List<X>>; typedef UserId = int;
このように定義した型は、新たな型という扱いではなくちゃんと別名になるようです。
しかしまだ仕様が確定したわけではないと思います。
上記コメントの時点から半年以上経っていて、いつになるのかわかりません。
他の新機能の導入に人手を取られているようです。
気長に待ちましょう。
Dart 2.13 以降の typedef
Dart 2.13 にて typedef が関数以外の型にも使えるようになりました。
しかし typedef はあくまで別名であって元の型と同一なので、Provider.of<T> を使うときに別名で区別しようとしてもダメでした。
【Flutter】依存オブジェクトの注入
1ヶ月ちょっと前に Flutter の provider というパッケージに関する記事を書きました。
そこでは、provider の機能の一つとして「DI の仕組みを提供」と説明しています。
しかし記事を複雑化するのを避けて掘り下げないままにしました。
代わりにここで補足しておこうと思います。
記事更新情報
- 2019/12/15
- 2019/11 下旬の provider 3.2.0 で 各プロバイダの
builderという引数名がcreateに変わりましたので、本記事の関連箇所を更新しました。
- 2019/11 下旬の provider 3.2.0 で 各プロバイダの
- 2020/5/8
- provider 4.1.0 によって異なる書き方ができるようになった旨を少し追記しました。
DI(Dependency Injection)とは
DI はデザインパターンの一つであり、依存性の注入 と訳されることが多いものです。
とっつきにくい言葉です。
それを次の記事ではとてもわかりやすく解説されています。
PHP のコードが出てきますが、Java 等に似た文法で理解は難しくないと思います。
オブジェクト A の中でオブジェクト B を生成すると、A は B に強く依存してしまいます。
それを避ける方法が Dependency Injection のはずです。
それなのに、依存性の注入 という訳だと逆に依存させてしまうように聞こえますね。
上の記事の著者も「混乱の元」と考え、わかりやすい別表現で説明されています。
「dependency」は使われるオブジェクト(サービスと呼ぶ)であり、「injection」とはそのオブジェクト(=サービス)を、それを使うオブジェクト(クライアントと呼ぶ)に渡すことです。
Dart におけるオブジェクトの注入
void main() { final service = Service(); final client = Client(service); // ServiceをClientに渡す(注入) client.doSomething(); }
class Service { void doSomething() { print('ServiceのdoSomething()が実行されました。'); } }
class Client { Service _service; Client(this._service); // Serviceを受け取る void doSomething() { _service.doSomething(); } }
外から Client に Service のオブジェクトを渡しています。
しかしこれでは単に注入しただけになっていて、Client は Service への依存が強いままです。
Service2 というオブジェクトを渡したくても、Client は Service しか受け取れません。
Dart における「抽象的な」オブジェクトの注入
強く依存しないようにしてこそ DI と呼べると思います。
そうするには、OOP の特性の一つである多態性を活用できます。
「使われるオブジェクト」の共通インタフェース(例: ServiceInterface)を Client が受けるようにすれば、ServiceInterface を実装した Service と Service2 はどちらも渡すことができます。
void main() { Client(Service()).doSomething(); // ServiceのdoSomething()が実行されました。 Client(Service2()).doSomething(); // Service2のdoSomething()が実行されました。 }
abstract class ServiceInterface { void doSomething(); }
class Service extends ServiceInterface { void doSomething() { print('ServiceのdoSomething()が実行されました。'); } }
class Service2 extends ServiceInterface { void doSomething() { print('Service2のdoSomething()が実行されました。'); } }
class Client { ServiceInterface _service; Client(this._service); void doSomething() { _service.doSomething(); } }
インタフェース
Dart には interface というキーワードは存在しないそうです。
共通のインタフェースを用意するには 暗黙的なインタフェース か 抽象クラス を使います。
ここでは、中身を定義しない抽象メソッドを用意したかったので abstract を付けて抽象クラスにしました。
テスタビリティ
抽象的なオブジェクトにしか依存しなくなると、テストしやすくもなります。
ServiceInterface を実装したクラスを Service の代わりに使ってテストできます。
例えば Service が DB を必要とするものであっても、DB 処理をなくしたテスト用クラスを使えます。
注入の方法
注入する方法は複数あり、先ほど参考にしたページでは次の3つが挙げられています。
コンストラクタインジェクション: コンストラクタに渡すセッターインジェクション: セッターを使って渡すプロパティインジェクション: プロパティに直接代入して渡す
Flutter 自体でも、Widget に child という引数で様々な Widget を渡せる仕組みは DI です。
コンストラクタに渡しているのでコンストラクタインジェクションですね。
この記事で試そうとしている provider の利用は、上の3つのどれでもないもう一つの方法になります。 *1
Flutter における DI の例
スイッチの On/Off で2進数/10進数の表示を切り替えられるカウンターのサンプルです。

注入するもの(10進数用と2進数用のカウンターのオブジェクト)を差し替えることで実現しています。
ちょっと強引になってしまっていますが、雰囲気を感じてください…。
*2
※コードは一部省略しています。
完全なコードは下記リポジトリにあります。
class _CounterText extends StatelessWidget { @override Widget build(BuildContext context) { final counter = Provider.of<CounterInterface>(context); return Column( children: <Widget>[ Text(counter.runtimeType.toString()), Text(counter.numberString), ], ); } }
カウンターの種類と数を表示する Widget です。
これがオブジェクト注入先の Client です(他の Widget にも注入していますが、ここがメイン)。
Widget ツリーの上方で provider を使ってオブジェクトが渡され、ここで受け取ります。
受け取ったオブジェクトの具体的な処理などについては、このクラスは知りません。
知っているのは下記の CounterInterface を実装していることと使い方だけです。
型名(具象クラス名)を runtimeType で得られるので、取得して表示するようにしています。
abstract class CounterInterface with ChangeNotifier { int _number = 0; int get number => _number; String get numberString; void setNumber(int number) => _number = number; void increment() { _number++; notifyListeners(); } }
この抽象クラスを実装した具象クラス(10進数用と2進数用のカウンターのモデル)を作ります。
numberString というゲッターの戻り値だけは次のように具象クラスで設定しています。
class DecCounter extends CounterInterface { @override String get numberString => _number.toString(); } class BinCounter extends CounterInterface { @override String get numberString => _number.toRadixString(2); }
スイッチを操作したとき、これらのカウンターを差し替えます。
そのために、使うカウンターのオブジェクトをどこかの変数に持たせます。
しかし、それだけでは表示は更新されませんので、リビルドが必要になります。
その方法は複数あります。
- StatefulWidget にカウンター用プロパティを持たせ、差し替え時に
setState()で全体リビルド setState()を使わずに、差し替え時にChangeNotifierProvider等によって通知してリビルド
前者を使うと、provider を使わなくても機能を実現できてしまうのでやめました。*3
また、後者のほうにも問題があります。
CounterInterface counter = DecCounter(); ChangeNotifierProvider<CounterInterface>.value( value: counter, child: ..., ) // スイッチ操作時のカウンター差し替え counter = BinCounter();
このようにすればカウンターの差し替えを下位 Widget に伝えることができそうな気がします。
ところが、これでは反映されません。
カウンターの値が変わったら通知されますが、カウンター自体の変更は通知されないのです。
これを解決するために、次の CounterContainer を咬ませることにしました。
class CounterContainer with ChangeNotifier { /// ここにカウンターのインスタンスを持たせる CounterInterface _counter; CounterInterface get counter => _counter; /// カウンターを差し替え、そのことを通知する set newCounter(CounterInterface counter) { _counter = counter; notifyListeners(); } }
MultiProvider( providers: [ ChangeNotifierProvider<CounterContainer>( create: (_) { // カウンターの入れ物を生成 // 最初は10進数のカウンターを入れておく return CounterContainer()..newCounter = DecCounter(); }, ), Consumer<CounterContainer>( // カウンターが差し替えられるたびにこのbuilderが呼ばれる builder: (_, container, __) { return ChangeNotifierProvider<CounterInterface>.value( value: container.counter, child: ..., ); }, ), ], )
CounterContainer の _counter にカウンターのオブジェクトを持たせています。
差し替えたら notifyListeners() で通知されるので、カウンター自体の変更が通知されない問題は解決です。
その通知は Consumer<CounterContainer>() に伝わって builder が呼ばれます。
そこに ChangeNotifierProvider<CounterInterface>.value() があり、新たなカウンターをセットします。
*4
この注入部分の他にボタンやスイッチの記述も合わせたものが下記になります。
コードはこれで終わりです。
class DependencyInjectionPage extends StatelessWidget { @override Widget build(BuildContext context) { // ここはほぼ先ほどの説明のとおり return MultiProvider( providers: [ ChangeNotifierProvider<CounterContainer>( create: (_) => CounterContainer()..newCounter = DecCounter(), ), Consumer<CounterContainer>( builder: (_, container, __) { return ChangeNotifierProvider<CounterInterface>.value( value: container.counter, child: Scaffold( appBar: AppBar(actions: <Widget>[_Switch()]), body: _CounterText(), floatingActionButton: _FloatingButton(), ), ); }, ), ], ); } } class _Switch extends StatelessWidget { @override Widget build(BuildContext context) { final container = Provider.of<CounterContainer>(context, listen: false); final counter = container.counter; return Switch( value: counter.runtimeType == BinCounter, onChanged: (value) { // スイッチを切り替えたときにカウンターを差し替える container.newCounter = value ? BinCounter() : DecCounter(); // 新しいカウンターは値を持たないので、元の値をセットする container.counter.setNumber(counter.number); }, ); } } class _FloatingButton extends StatelessWidget { @override Widget build(BuildContext context) { final counter = Provider.of<CounterInterface>(context, listen: false); return FloatingActionButton( onPressed: counter.increment, ); } }
二つのプロバイダで CounterContainer と CounterInterface を注入しているのは少しややこしいですね。
Client である _CounterText に対して CounterContainer(カウンターの入れ物丸ごと)を渡しても機能を実現できるのですが、アンチパターンとされるサービスロケータのようになってしまうため、Service に相当する CounterInterface(入れ物の中身だけ)を注入すべきと考えました。
追記(2020/5/8)
provider が先日 v4.1.0 になり、各 provider に Builder の機能に相当する builder という引数が追加され、Consumer を使わなくても直前の ChangeNotifierProvider で設定された値を取得できるようになりました。
上記のコードを更新していませんが、リポジトリでは更新済み ですので、そちらをご覧ください。
まとめ
苦労が見えるサンプルだったと思います。
provider によって楽をできたのは間違いないですが、とても簡単というわけでもありません。
少し癖があって、慣れが必要です。
このサンプルで癖を理解できたなら、きっと様々なことに応用できます。
しかし場合によっては、provider を使わないのが好ましいこともあります。
例えば、遷移先のページに値を渡すのはコンストラクタインジェクションのほうがシンプルです。
*5
Navigator.of(context).push( MaterialPageRoute<void>(builder: (context) => NextPage(foo)), )
また、provider は Widget を子とするので、UI 層のコードで用いるものです。
他の層でデータ保存処理のオブジェクトをどこかに注入するといった用途には使えません。
実装したい機能に応じた注入方法を選びましょう。
*1:Widget 間で値をやり取りする必要がなかったり、provider の便利な機能(値変更の伝播、Widget ツリーから除去されるときの自動破棄など)を使わなかったりする場合の単純な DI には、他にパッケージ(get_it 等)のほうが向いているかもしれません。用途に適したものを選びましょう。
*2:2進数/10進数の値を返すメソッドを持ったクラスのオブジェクトを共通のカウンターモデルに注入すればもっとシンプルにできますが、モデルではなく Widget に対して provider を使ってカウンターを注入するサンプルとしてこうなりました。
*3:簡単に機能を実現できるのは良いことですが、そういうやり方では大きなアプリになったときに困る場合が出てくるかもしれません。
*4:Consumer + ChangeNotifierProvider の代わりに ChangeNotifierProxyProvider が使えそうですが、使えません。 ChangeNotifierProxyProvider は create で最初にインスタンスを生成してから update が呼ばれるたびにそのインスタンスを使い回すものであり、このサンプルのようにカウンターを差し替えるたびにインスタンスが変わる場合には使い方が合いません。
【SQLite/MySQL】グループごとの上位N件ずつを取得
MySQL でグループごとに上位のN件ずつを取得する方法は以前に書きました。
サーバサイドの MySQL はこれで解決しました。
しかし、スマホアプリ側で似たテーブル構成にしておいて同様のクエリを使いたくてもできません。
そこで、Android や iOS のアプリ開発でよく使われる SQLite でも実現できる方法を調べました。
SQLite の Window 関数について
新しいバージョンの SQLite では Window 関数が使えます。
しかし、この記事を書いている時点の Android / iOS ではまだ使えません。
詳細は以前に書いた下記記事をご覧ください。
【Android / iOS】スマホOSとSQLiteのバージョン対応 - のんびり精進
参考ページ
ここのベストアンサーの方法を参考にしています。
Window 関数も MySQL のユーザ定義関数も使われていません。
SQLite でも使えるはずです。
また、MySQL でももう一つの方法として使えそうです。
SELECT b.BookId, a.AuthorId, a.AuthorName, b.Title FROM Author a join Book b on a.AuthorId = b.AuthorId where (select count(*) from book b2 where b2.bookId <= b.BookId and b2.AuthorId = b.AuthorId ) <= 2;
- 書籍のテーブル(著者のIDも持つ)と著者のテーブルがある
- 著者ごとに書籍ID順で2件ずつを取得する
お断り
SQLite で動作確認済みなのですが、その後に記事を書く時点では諸事情により SQLite で確認しにくかったため、DDL・実行計画などは MySQL のものを掲載しています。
使用するデータ
MySQL の記事で使ったのと同じデータで試します。
※正規化していないのはシンプルな例にするためですので、ご了承ください。
CREATE TABLE students ( id int, class varchar(8), name varchar(16), score int );
INSERT INTO students VALUES (1, 'A組', '佐藤', 95), (2, 'A組', '鈴木', 87), (3, 'A組', '高橋', 80), (4, 'B組', '田中', 100), (5, 'B組', '渡辺', 72), (6, 'B組', '伊藤', 53), (7, NULL, '山本', 99), (8, NULL, '中村', 96), (9, NULL, '小林', 93);
- クラスごとに点数が高い順に2名ずつ取得
- クラスが不明(
classがNULL)な生徒もいる
→ その生徒たちの中からも上位2名を取得
COALESCE() を使う方法
SELECT s.* FROM students AS s WHERE ( SELECT COUNT(*) FROM students AS s2 WHERE COALESCE(s2.class, '') = COALESCE(s.class, '') AND s2.score >= s.score ) <= 2 ORDER BY s.class, s.score DESC;
SQLite でも MySQL でも期待通りの取得ができました。
MySQL の記事のクエリよりシンプルです。
| id | class | name | score |
|---|---|---|---|
| 7 | NULL | 山本 | 99 |
| 8 | NULL | 中村 | 96 |
| 1 | A組 | 佐藤 | 95 |
| 2 | A組 | 鈴木 | 87 |
| 4 | B組 | 田中 | 100 |
| 5 | B組 | 渡辺 | 72 |
参考ページのクエリとの違いは次のとおりです(JOIN の有無は除く)。
- 書籍IDは昇順、点数は降順なので、不等号が逆
・ 参考クエリ:b2.bookId <= b.BookId
・ このクエリ:s2.score >= s.score classがNULLになっている場合を考慮してCOALESCE()を使用
COALESCE() の第2引数を空文字('')にしましたが、念のために class と同じ文字列型にしただけです。
WHERE 句での比較にしか使っていないので、別の型でも問題ありません。
実行計画
+----+--------------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ | 1 | PRIMARY | s | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using filesort | | 2 | DEPENDENT SUBQUERY | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 33.33 | Using where | +----+--------------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
COALESCE() を使わない方法
COALESCE() は効率が悪く思えるので、使わない版も試しました。
SELECT s.* FROM students AS s WHERE ( SELECT COUNT(*) FROM students AS s2 WHERE (s2.class = s.class OR (s2.class IS NULL AND s.class IS NULL)) AND s2.score >= s.score ) <= 2 ORDER BY s.class, s.score DESC;
違いは、WHERE 句の条件のうちの前半だけです。
- COALESCE() 使用版
COALESCE(s2.class, '') = COALESCE(s.class, '')
- COALESCE() 不使用版
・s2.classとs.classが同じ値(NULL以外)
または
・s2.classとs.classがどちらもNULL
(s2.class = s.class OR (s2.class IS NULL AND s.class IS NULL))
実行計画
+----+--------------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ | 1 | PRIMARY | s | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using filesort | | 2 | DEPENDENT SUBQUERY | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 11.11 | Using where | +----+--------------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
インデックスの効果
ALTER TABLE students ADD INDEX idx_class_score(class, score);
このように class と score の複合インデックスを設定し、実行計画の変化を見てみました。
COALESCE() 使用版の実行計画
+----+--------------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+-----------------------------+ | 1 | PRIMARY | s | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using filesort | | 2 | DEPENDENT SUBQUERY | s2 | NULL | index | NULL | idx_class_score | 40 | NULL | 9 | 33.33 | Using where; Using index | +----+--------------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+-----------------------------+
相関サブクエリのほうでインデックスが使われるようになりましたが、フルインデックススキャンです。
rows、filtered などは変化がありません。
インデックスがないより少しだけマシといったところでしょうか。
COALESCE() 不使用版の実行計画
+----+--------------------+-------+------------+-------------+-----------------+-----------------+---------+---------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------------+-------+------------+-------------+-----------------+-----------------+---------+---------+------+----------+-----------------------------+ | 1 | PRIMARY | s | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using filesort | | 2 | DEPENDENT SUBQUERY | s2 | NULL | ref_or_null | idx_class_score | idx_class_score | 35 | s.class | 6 | 33.33 | Using where; Using index | +----+--------------------+-------+------------+-------------+-----------------+-----------------+---------+---------+------+----------+-----------------------------+
こちらは効果が出ていますが、効率が良いとは言えないと思います。
とは言え、MySQL の Window 関数でも非効率な実行計画になっていたことを考えると、強引にやっている割には良い結果なのかもしれません。
【Android / iOS】スマホOSとSQLiteのバージョン対応
スマホアプリ内のデータベースと言えば、SQLite を使うことが多いと思います。
自作のアプリでも SQLite を使っていましたが、非常にシンプルなクエリのみでした。
そのためあまり気にしていなかったのですが、新たなアプリで少し複雑なクエリが必要になって調べたところ、他の RDBMS のようにはできないことがありました。
現時点で機能が不足していても、新しいスマホ OS バージョンではサポートする SQLite のバージョンが上がり、今後だんだん解消されると思います。
しかし、古い OS までアプリを対応させる場合には考慮が必要になりそうなので、情報をまとめておきます。
SQLite と Android のバージョン
| SQLite | Android API | Android OS |
|---|---|---|
| 3.19 | 27 | 8.1 |
| 3.18 | 26 | 8.0 |
| 3.9 | 24 | 7.0 |
| 3.8 | 21 | 5.0 |
| 3.7 | 11 | 3.0.x |
| 3.6 | 8 | 2.2.x |
android.database.sqlite | Android Developers
最新の情報は上記リンク先をご覧ください。
また、この表では間が抜けていますが、次のページにはもっと細かい情報が載っています。
必要に応じて確認してください。
database - Version of SQLite used in Android? - Stack Overflow
SQLite と iOS のバージョン
| SQLite | iOS |
|---|---|
| 3.24.0 | 12.1 |
| 3.24.0 | 12.0 |
| 3.19.3 | 11.0 |
| 3.16.0 | 10.3.1 |
| 3.14.0 | 10.2 |
| 3.14.0 | 10.0 GM |
| 3.13.0 | 10.0 beta 2 |
| 3.8.10.2 | 9.3.5 |
| 3.8.10.2 | 9.3.1 |
| 3.8.8 | 9.0 |
| 3.8.5 | 8.4 |
| 3.8.5 | 8.2 |
| 3.7.13 | 8.1 |
| 3.7.13 | 8.0.2 |
| 3.7.13 | 7.0.6 |
| 3.7.13 | 7.0 |
| 3.7.13 | 6.0.1 |
| 3.7.7 | 5.1.1 |
| 3.6.23.2 | 4.2.0 |
SQLite version (bundled with OS) · yapstudios/YapDatabase Wiki · GitHub
最新の情報は上記リンクの先をご覧ください。
(この記事の対象外ですが)Mac OS の情報も載っています。
Bulk Insert
INSERT INTO user (id, name) VALUES (1, '佐藤'); INSERT INTO user (id, name) VALUES (2, '鈴木'); INSERT INTO user (id, name) VALUES (3. '高橋');
普段サーバサイドで MySQL を使うことが多いのですが、複数のデータの INSERT はこのようにはしません。
この程度の数なら良いのですが、もっと多くなると一件ずつでは非常にパフォーマンスが悪くなるので、次のようにまとめて一度に行っています(Bulk Insert)。
INSERT INTO user (id, name) VALUES (1, '佐藤'), (2, '鈴木'), (3. '高橋');
SQLite ではどうなのでしょうか。
公式の リリースノート を見てみます。
2012-03-20 (3.7.11)
- Enhance the INSERT syntax to allow multiple rows to be inserted via the VALUES clause.
この部分が Bulk Insert のことになりますね。
SQLite 3.7.11 から対応しているようです。
これより前の OS バージョンは、そろそろサポート対象外にしても良さそうなほど古くなっていますね。
あまり問題にならないかもしれません。
UPSERT
レコードが既に存在していれば UPDATE し、なければ INSERT する機能です。
これは SQLite 3.24.0 でサポートされています。
RDBMS によって使い方が異なりますが、「Add support for PostgreSQL-style UPSERT.」と書かれているので SQLite は PostgreSQL 風です。
ON CONFLICT のやつです。
ちなみに、INSERT OR REPLACE はもっと古くから対応しているようです。
UPSERT とは似て非なるものなので代わりに使えるとは限りません。
更新の仕方もたぶん違います(REPLACE のほうはおそらく DELETE と INSERT が起こります)。
Window 関数
古い MySQL のバージョンで Window 関数に対応していない件について、以前に記事を書きました。
【MySQL】グループごとの上位N件ずつを取得 - のんびり精進
新たに作っているアプリでサーバサイド(MySQL)とアプリ(SQLite)で似たテーブル構造にしておいて、クエリも似た感じでできればと思ったのですが、SQLite でも Window 関数の問題にぶち当たりました。
SQLite での Window 関数の対応状況は、次のページの「6. History」という部分に書かれています。
Window function support was first added to SQLite with release version 3.25.0 (2018-09-15).
SQLite 3.25.0 から対応したと書かれています。
SQLite と Android / iOS とのバージョン対応表を先ほど載せましたが、その表で確認すると・・・
まだ対応していません!
残念です。
あと少し、と言いたいところですが、対応するバージョンが出てきても対応しないバージョンまでサポートすることを考えると、本格的に使うのはかなり先になりそうです。
SQLite の Window 関数の動作と機能
ちなみに、先ほどのページを見ると SQLite の Window 関数について次のように書かれています。
The SQLite developers used the PostgreSQL window function documentation as their primary reference for how window functions ought to behave. Many test cases have been run against PostgreSQL to ensure that window functions operate the same way in both SQLite and PostgreSQL.
PostgreSQL の Window 関数と同じ動作となることを考慮しながら作られているようです。
In SQLite version 3.28.0 (2019-04-16), windows function support was extended to include the EXCLUDE clause, GROUPS frame types, window chaining, and support for "
PRECEDING" and " FOLLOWING" boundaries in RANGE frames.
SQLite 3.28.0 では機能がさらに拡張されるとのことです。
今は少し不十分でも、今後は便利なものになっていきそうですね。
【Dart】Mapの順番(HashMap, LinkedHashMap, SplayTreeMap)
様々な言語によくあるハッシュマップでは順番の概念がなく、その一方で、PHP(連想配列)など一部の言語の実装では順番があったりします。 言語を切り替えて開発したりしばらく使わなかったりすると混乱する部分です。
Dart の Map についてはどうなっているのか知らなかったので調べてみました。
いきなり結論
Map順番ありLinkedHashMap順番ありHashMap順番なしSplayTreeMap順番あり(追加順ではなくキーの順)
Map は基本的に LinkedHashMap と同じになるようです。
参考にしたのは次の情報です。
Does dart automatically determine which map type to use? - Stack Overflow
If you navigate to our docs:
- https://api.dartlang.org/dev
- dart:core (https://api.dartlang.org/dev/dart-core/dart-core-library.html)
- Map (https://api.dartlang.org/dev/dart-core/Map-class.html)
You'll see the following description:
Maps, and their keys and values, can be iterated. The order of iteration is defined by the individual type of map.
And for the default constructor (the one used for {} syntax, as well):
Creates a LinkedHashMap instance that contains all key/value pairs of other.
検証
Map
void main() { final Map m = { 3: 'orange', 2: 'apple', 1: 'banana' }; m.forEach((k, v) => print('$k: $v')); }
3: orange 2: apple 1: banana
記述したとおりの順番になっています。
LinkedHashMap
dart:collection のインポートが必要です。
import 'dart:collection'; void main() { final m = LinkedHashMap(); // final m = Map(); // これに変えても同じ結果になる m[3] = 'orange'; m[2] = 'apple'; m[1] = 'banana'; m.forEach((k, v) => print('$k: $v')); }
3: orange 2: apple 1: banana
追加順のままになりました。
HashMap
dart:collection のインポートが必要です。
import 'dart:collection'; void main() { final m = HashMap(); m[3] = 'orange'; m[2] = 'apple'; m[1] = 'banana'; m.forEach((k, v) => print('$k: $v')); }
1: banana 2: apple 3: orange
任意の順番になりました(たまたまキーの順番に並んでいますが、常にそうなるとは限らないはずです)。
他の言語でよくあるハッシュマップと同じですね。
SplayTreeMap
四種類の中で SplayTreeMap は一番わかりにくいと思います。
探した情報の中では次の解説が明解でした。
What are the differences between the different Map implementations in Dart? - Stack Overflow
A splay tree is a good choice for data that is stored and accessed frequently, like caches. The reason is that they use tree rotations to bring up an element to the root for better frequent accesses. The performance comes from the self-optimization of the tree. That is, frequently accessed elements are moved nearer to the top. If however, the tree is equally often accessed all around, then there's little point of using a splay tree map.
頻繁にアクセスする要素を木構造のルートのほうに寄せる最適化をしてくれるので、要素のアクセス頻度に偏りがある用途ではこれを使うと効率が良さそうです。
そうでない場合にはメリットが少ないようです。
追記(2020-1-30)
SplayTreeMap にはもう一つ大事な特徴があることがわかりました。
Dart/Flutter Map, HashMap Tutorial with Examples - BezKoder
SplayTreeMap iterates the keys in sorted order.
キーの順にイテレートしてくれるとのことです。
これは活用できそうな機能ですね。
試してみると、キーと無関係な順序(3, 2, 1)で要素を追加しても、イテレーションは確かにキーの順になりました(1, 2, 3)。
import 'dart:collection'; void main() { final m = SplayTreeMap(); m[3] = 'orange'; m[2] = 'apple'; m[1] = 'banana'; m.forEach((k, v) => print('$k: $v')); }
1: banana 2: apple 3: orange
公式ドキュメント にも順序のことが書かれていますが、アクセス頻度によってツリー内の最適な位置に配置される件と混同していました。
読み直すと、順序や同一性判定のための比較関数をコンストラクタに渡せる旨も書かれていました。
Keys of the map are compared using the compare function passed in the constructor, both for ordering and for equality.
パフォーマンスについては、先ほどの Stack Overflow ではどの操作も O(log n) の計算量で済むことが説明されていて、この情報が正しければ効率はなかなか良いと言えます。
It performs basic operations such as insertion, look-up and removal in O(log(n)) amortized time.